")
What are Massive Language Fashions?
Massive Language Fashions (LLMs) are superior synthetic intelligence (AI) programs designed to course of, perceive, and generate human-like textual content. They’re primarily based on deep studying strategies and skilled on huge datasets, often containing billions of phrases from numerous sources like web sites, books, and articles. This in depth coaching permits LLMs to understand the nuances of language, grammar, context, and even some elements of normal information.
Some fashionable LLMs, like OpenAI’s GPT-3, make use of a sort of neural community referred to as a transformer, which permits them to deal with advanced language duties with outstanding proficiency. These fashions can carry out a variety of duties, equivalent to:
- Answering questions
- Summarizing textual content
- Translating languages
- Producing content material
- Even participating in interactive conversations with customers
As LLMs proceed to evolve, they maintain nice potential for enhancing and automating numerous functions throughout industries, from customer support and content material creation to training and analysis. Nonetheless, in addition they elevate moral and societal issues, equivalent to biased conduct or misuse, which have to be addressed as know-how advances.

In style Examples of Massive Language Fashions
Listed below are just a few outstanding examples of LLMs used broadly in numerous {industry} verticals:
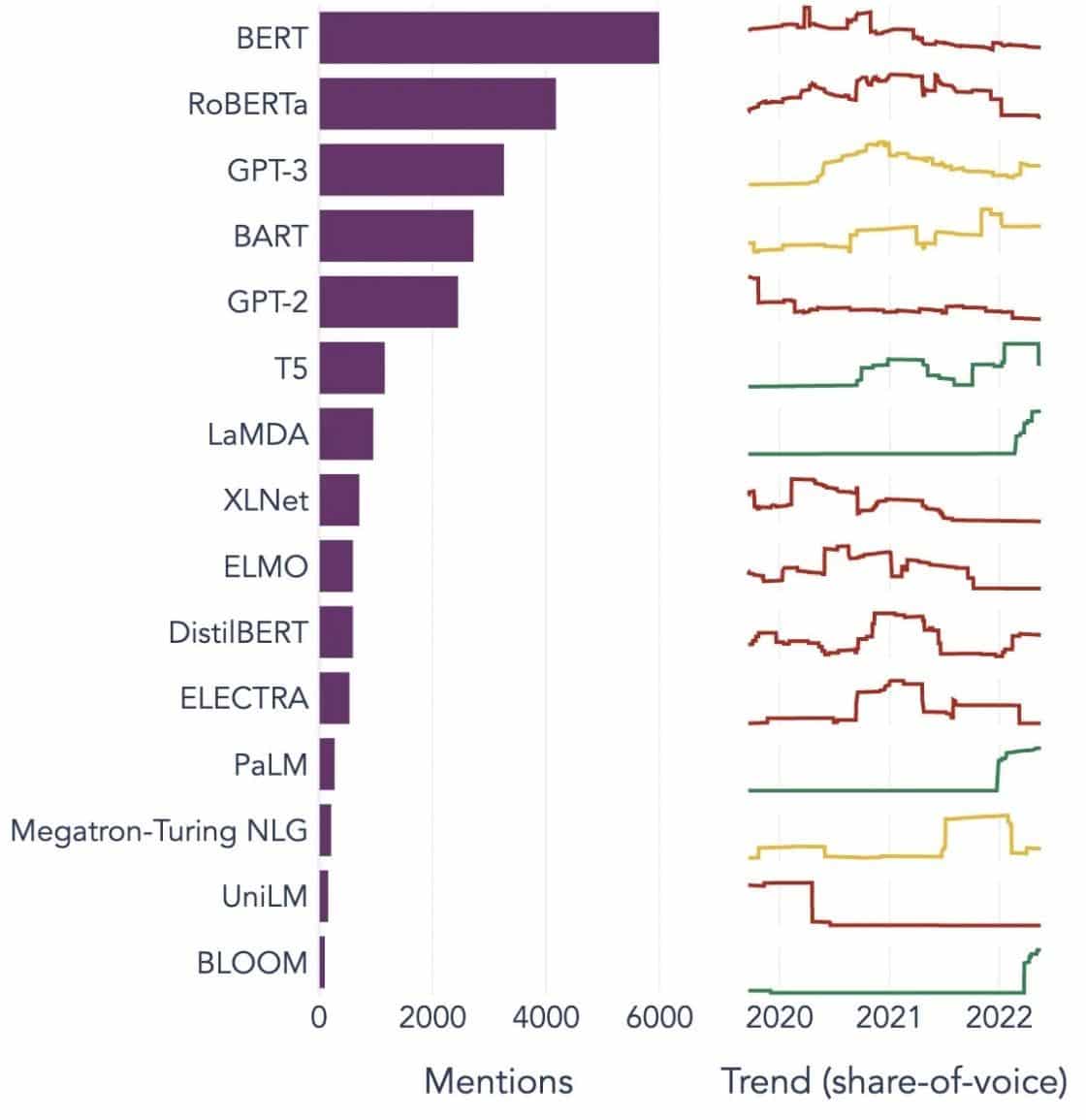
Picture Supply: Towards data Science
How are LLM fashions skilled?
Coaching massive language fashions (LLMs) is sort of a feat that entails a number of essential steps. Right here’s a simplified, step-by-step rundown of the method:
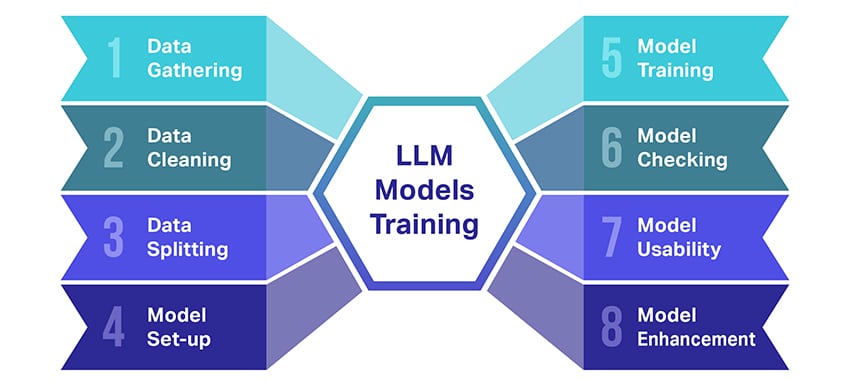
- Gathering Textual content Information: Coaching an LLM begins with the gathering of an enormous quantity of textual content knowledge. This knowledge can come from books, web sites, articles, or social media platforms. The intention is to seize the wealthy variety of human language.
- Cleansing Up the Information: The uncooked textual content knowledge is then tidied up in a course of referred to as preprocessing. This contains duties like eradicating undesirable characters, breaking down the textual content into smaller elements referred to as tokens, and getting all of it right into a format the mannequin can work with.
- Splitting the Information: Subsequent, the clear knowledge is break up into two units. One set, the coaching knowledge, can be used to coach the mannequin. The opposite set, the validation knowledge, can be used later to check the mannequin’s efficiency.
- Organising the Mannequin: The construction of the LLM, often called the structure, is then outlined. This entails choosing the kind of neural community and deciding on numerous parameters, such because the variety of layers and hidden items throughout the community.
- Coaching the Mannequin: The precise coaching now begins. The LLM mannequin learns by trying on the coaching knowledge, making predictions primarily based on what it has discovered thus far, after which adjusting its inside parameters to cut back the distinction between its predictions and the precise knowledge.
- Checking the Mannequin: The LLM mannequin’s studying is checked utilizing the validation knowledge. This helps to see how properly the mannequin is performing and to tweak the mannequin’s settings for higher efficiency.
- Utilizing the Mannequin: After coaching and analysis, the LLM mannequin is prepared to be used. It could possibly now be built-in into functions or programs the place it’ll generate textual content primarily based on new inputs it’s given.
- Bettering the Mannequin: Lastly, there’s all the time room for enchancment. The LLM mannequin might be additional refined over time, utilizing up to date knowledge or adjusting settings primarily based on suggestions and real-world utilization.
Bear in mind, this course of requires vital computational assets, equivalent to highly effective processing items and huge storage, in addition to specialised information in machine studying. That’s why it’s often accomplished by devoted analysis organizations or corporations with entry to the required infrastructure and experience.
Does the LLM Depend on Supervised or Unsupervised Studying?
Massive language fashions are often skilled utilizing a way referred to as supervised studying. In easy phrases, this implies they be taught from examples that present them the right solutions.

So, in case you feed an LLM a sentence, it tries to foretell the subsequent phrase or phrase primarily based on what it has discovered from the examples. This fashion, it learns how one can generate textual content that is smart and matches the context.
That stated, typically LLMs additionally use a little bit of unsupervised studying. That is like letting the kid discover a room full of various toys and study them on their very own. The mannequin appears to be like at unlabeled knowledge, studying patterns, and buildings with out being informed the “proper” solutions.
Supervised studying employs knowledge that’s been labeled with inputs and outputs, in distinction to unsupervised studying, which doesn’t use labeled output knowledge.
In a nutshell, LLMs are primarily skilled utilizing supervised studying, however they will additionally use unsupervised studying to boost their capabilities, equivalent to for exploratory evaluation and dimensionality discount.
What’s the Information Quantity (In GB) Obligatory To Practice A Massive Language Mannequin?
The world of potentialities for speech knowledge recognition and voice functions is immense, and they’re being utilized in a number of industries for a plethora of functions.
Coaching a big language mannequin isn’t a one-size-fits-all course of, particularly in relation to the info wanted. It is dependent upon a bunch of issues:
- The mannequin design.
- What job does it have to do?
- The kind of knowledge you’re utilizing.
- How properly would you like it to carry out?
That stated, coaching LLMs often requires a large quantity of textual content knowledge. However how huge are we speaking about? Properly, suppose method past gigabytes (GB). We’re often taking a look at terabytes (TB) and even petabytes (PB) of information.
Take into account GPT-3, one of many largest LLMs round. It’s skilled on 570 GB of text data. Smaller LLMs would possibly want much less – possibly 10-20 GB and even 1 GB of gigabytes – but it surely’s nonetheless quite a bit.

However it’s not simply concerning the measurement of the info. High quality issues too. The info must be clear and diverse to assist the mannequin be taught successfully. And you’ll’t neglect about different key items of the puzzle, just like the computing energy you want, the algorithms you utilize for coaching, and the {hardware} setup you’ve gotten. All these elements play an enormous half in coaching an LLM.
The Rise of Massive Language Fashions: Why They Matter
LLMs are not only a idea or an experiment. They’re more and more taking part in a vital position in our digital panorama. However why is that this taking place? What makes these LLMs so necessary? Let’s delve into some key elements.
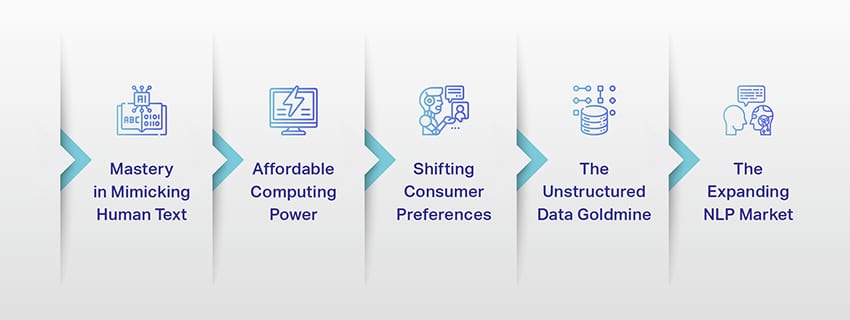
1. Mastery in Mimicking Human Textual content
LLMs have reworked the best way we deal with language-based duties. Constructed utilizing strong machine studying algorithms, these fashions are geared up with the flexibility to grasp the nuances of human language, together with context, emotion, and even sarcasm, to some extent. This functionality to imitate human language isn’t a mere novelty, it has vital implications.
LLMs’ superior textual content era skills can improve every part from content material creation to customer support interactions.
Think about with the ability to ask a digital assistant a posh query and getting a solution that not solely is smart, however can be coherent, related, and delivered in a conversational tone. That’s what LLMs are enabling. They’re fueling a extra intuitive and fascinating human-machine interplay, enriching consumer experiences, and democratizing entry to data.
2. Reasonably priced Computing Energy
The rise of LLMs wouldn’t have been potential with out parallel developments within the subject of computing. Extra particularly, the democratization of computational assets has performed a big position within the evolution and adoption of LLMs.
Cloud-based platforms are providing unprecedented entry to high-performance computing assets. This fashion, even small-scale organizations and unbiased researchers can prepare refined machine studying fashions.
Furthermore, enhancements in processing items (like GPUs and TPUs), mixed with the rise of distributed computing, have made it possible to coach fashions with billions of parameters. This elevated accessibility of computing energy is enabling the expansion and success of LLMs, resulting in extra innovation and functions within the subject.
3. Shifting Shopper Preferences
Shoppers at this time don’t simply need solutions; they need participating and relatable interactions. As extra folks develop up utilizing digital know-how, it’s evident that the necessity for know-how that feels extra pure and human-like is rising.LLMs provide an unmatched alternative to satisfy these expectations. By producing human-like textual content, these fashions can create participating and dynamic digital experiences, which may enhance consumer satisfaction and loyalty. Whether or not it’s AI chatbots offering customer support or voice assistants offering information updates, LLMs are ushering in an period of AI that understands us higher.
4. The Unstructured Information Goldmine
Unstructured knowledge, equivalent to emails, social media posts, and buyer evaluations, is a treasure trove of insights. It’s estimated that over 80% of enterprise knowledge is unstructured and rising at a price of 55% per yr. This knowledge is a goldmine for companies if leveraged correctly.
LLMs come into play right here, with their potential to course of and make sense of such knowledge at scale. They will deal with duties like sentiment evaluation, textual content classification, data extraction, and extra, thereby offering precious insights.
Whether or not it’s figuring out developments from social media posts or gauging buyer sentiment from evaluations, LLMs are serving to companies navigate the big quantity of unstructured knowledge and make data-driven selections.
5. The Increasing NLP Market
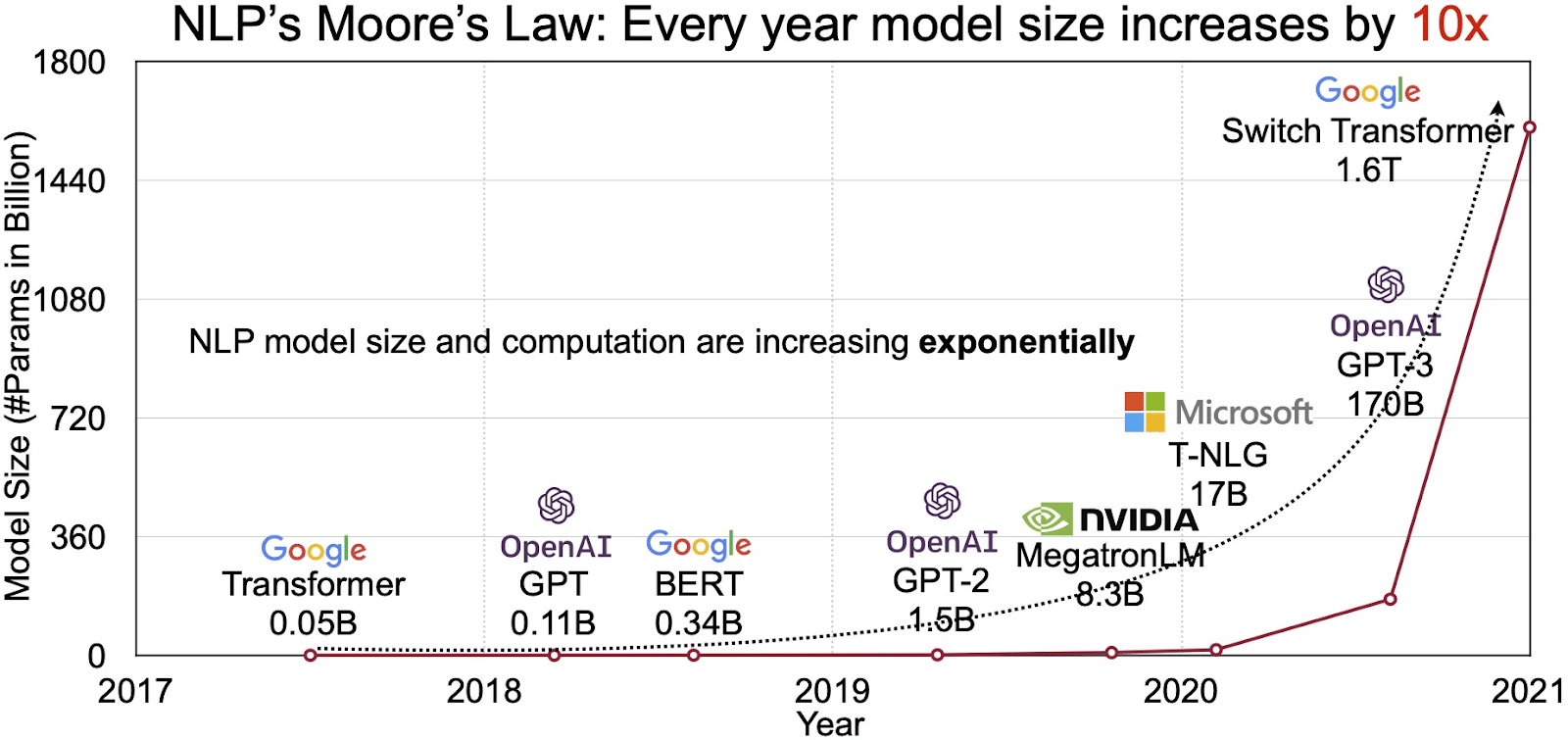
The potential of LLMs is mirrored within the quickly rising marketplace for pure language processing (NLP). Analysts challenge the NLP market to increase from $11 billion in 2020 to over $35 billion by 2026. However it’s not simply the market measurement that’s increasing. The fashions themselves are rising too, each in bodily measurement and within the variety of parameters they deal with. The evolution of LLMs through the years, as seen within the determine under (picture supply: hyperlink), underscores their rising complexity and capability.
In style Use Circumstances of Massive Language Fashions
Listed below are a number of the high and most prevalent use circumstances of LLM:
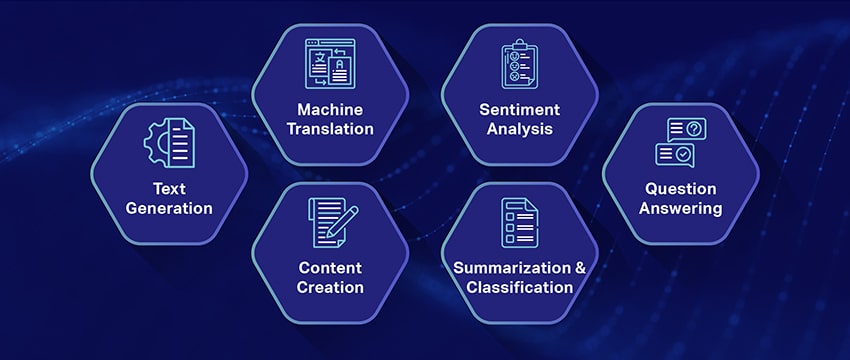
- Producing Pure Language Textual content: Massive Language Fashions (LLMs) mix the facility of synthetic intelligence and computational linguistics to autonomously produce texts in pure language. They will cater to numerous consumer wants equivalent to penning articles, crafting songs, or participating in conversations with customers.
- Translation by means of Machines: LLMs might be successfully employed to translate textual content between any pair of languages. These fashions exploit deep studying algorithms like recurrent neural networks to grasp the linguistic construction of each supply and goal languages, thereby facilitating the interpretation of the supply textual content into the specified language.
- Crafting Authentic Content material: LLMs have opened up avenues for machines to generate cohesive and logical content material. This content material can be utilized to create weblog posts, articles, and different forms of content material. The fashions faucet into their profound deep-learning expertise to format and construction the content material in a novel and user-friendly method.
- Analysing Sentiments: One intriguing utility of Massive Language Fashions is sentiment evaluation. On this, the mannequin is skilled to acknowledge and categorize emotional states and sentiments current within the annotated textual content. The software program can establish feelings equivalent to positivity, negativity, neutrality, and different intricate sentiments. This could present precious insights into buyer suggestions and views about numerous services and products.
- Understanding, Summarizing, and Classifying Textual content: LLMs set up a viable construction for AI software program to interpret the textual content and its context. By instructing the mannequin to grasp and scrutinize huge quantities of information, LLMs allow AI fashions to grasp, summarize, and even categorize textual content in numerous kinds and patterns.
- Answering Questions: Massive Language Fashions equip Query Answering (QA) programs with the aptitude to precisely understand and reply to a consumer’s pure language question. In style examples of this use case embody ChatGPT and BERT, which study the context of a question and sift by means of an enormous assortment of texts to ship related responses to consumer questions.
Shaip’s Providing
Shaip presents a variety of providers to assist organizations handle, analyze, and take advantage of their knowledge.
Information Net-Scraping
One key service supplied by Shaip is knowledge scraping. This entails the extraction of information from domain-specific URLs. By using automated instruments and strategies, Shaip can shortly and effectively scrape massive volumes of information from numerous web sites, Product Manuals, Technical Documentation, On-line boards, On-line Opinions, Buyer Service Information, Business Regulatory Paperwork and so forth. This course of might be invaluable for companies when gathering related and particular knowledge from a large number of sources.

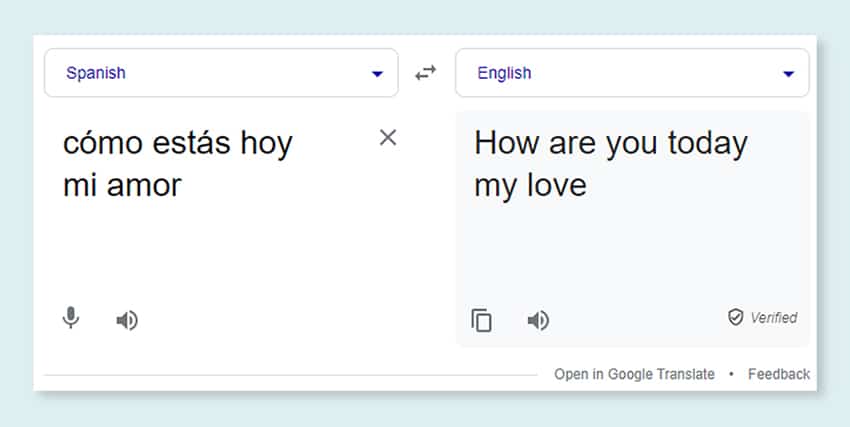
Machine Translation
Develop fashions utilizing in depth multilingual datasets paired with corresponding transcriptions for translating textual content throughout numerous languages. This course of helps dismantle linguistic obstacles and promotes the accessibility of knowledge.
Taxonomy Extraction & Creation
Shaip may also help with taxonomy extraction and creation. This entails classifying and categorizing knowledge right into a structured format that displays the relationships between totally different knowledge factors. This may be significantly helpful for companies in organizing their knowledge, making it extra accessible and simpler to investigate. For example, in an e-commerce enterprise, product knowledge is likely to be categorized primarily based on product sort, model, worth, and so forth., making it simpler for purchasers to navigate the product catalog.
Information Assortment
Our knowledge assortment providers present vital real-world or artificial knowledge essential for coaching generative AI algorithms and enhancing the accuracy and effectiveness of your fashions. The info is unbiased, ethically and responsibly sourced whereas preserving in thoughts knowledge privateness and safety.

Query & Answering
Query answering (QA) is a subfield of pure language processing centered on routinely answering questions in human language. QA programs are skilled on in depth textual content and code, enabling them to deal with numerous forms of questions, together with factual, definitional, and opinion-based ones. Area information is essential for growing QA fashions tailor-made to particular fields like buyer help, healthcare, or provide chain. Nonetheless, generative QA approaches enable fashions to generate textual content with out area information, relying solely on context.
Our staff of specialists can meticulously examine complete paperwork or manuals to generate Query-Reply pairs, facilitating the creation of Generative AI for companies. This strategy can successfully deal with consumer inquiries by mining pertinent data from an in depth corpus. Our licensed consultants make sure the manufacturing of top-quality Q&A pairs that span throughout numerous matters and domains.

Textual content Summarization
Our specialists are able to distilling complete conversations or prolonged dialogues, delivering succinct and insightful summaries from in depth textual content knowledge.

Textual content Technology
Practice fashions utilizing a broad dataset of textual content in numerous kinds, like information articles, fiction, and poetry. These fashions can then generate numerous forms of content material, together with information items, weblog entries, or social media posts, providing a cheap and time-saving answer for content material creation.
Speech Recognition
Develop fashions able to comprehending spoken language for numerous functions. This contains voice-activated assistants, dictation software program, and real-time translation instruments. The method entails using a complete dataset comprised of audio recordings of spoken language, paired with their corresponding transcripts.

Product Suggestions
Develop fashions utilizing in depth datasets of buyer shopping for histories, together with labels that time out the merchandise prospects are inclined to buy. The purpose is to supply exact solutions to prospects, thereby boosting gross sales and enhancing buyer satisfaction.
Picture Captioning
Revolutionize your picture interpretation course of with our state-of-the-art, AI-driven Picture Captioning service. We infuse vitality into photos by producing correct and contextually significant descriptions. This paves the best way for revolutionary engagement and interplay potentialities along with your visible content material on your viewers.

Coaching Textual content-to-Speech Providers
We offer an in depth dataset comprised of human speech audio recordings, very best for coaching AI fashions. These fashions are able to producing pure and fascinating voices on your functions, thus delivering a particular and immersive sound expertise on your customers.
