
It’s Monday morning. You open your laptop computer, and there it’s: an inbox flooded with vendor invoices, scanned receipts from the gross sales staff, and a dozen PDF contracts ready for assessment. It’s the digital equal of a paper mountain, and for many years, the problem was merely to get by means of it.
However now, there’s a brand new stress. The C-suite is asking about Generative AI. They goal to develop an inner chatbot able to answering questions on gross sales contracts, in addition to an AI software to research monetary studies. And all of a sudden, that mountain of messy paperwork isn’t simply an operational bottleneck; it’s the roadblock to your total AI technique.
This digital doc mountain is what we name unstructured knowledge. It’s the chaos of the true world, and in line with trade estimates, it accounts for 80-90% of a corporation’s knowledge. But, in a staggering disconnect, Deloitte’s findings reveal that solely 18% of firms have effectively extracted worth from this uncharted digital territory.
It is a sensible information to fixing the one greatest drawback holding again enterprise AI: turning your chaotic paperwork into clear, structured, LLM-ready knowledge.
Understanding the three forms of knowledge in your enterprise
It is the data that exists in its uncooked, native format. This knowledge accommodates the important context and nuance of enterprise operations, but it surely does not match into the inflexible rows and columns of a conventional database.
Let’s shortly make clear the three forms of knowledge you’ll encounter:
- Structured: That is extremely organized knowledge that adheres to a predefined mannequin, becoming neatly into spreadsheets and relational databases. Consider buyer names, addresses, and telephone numbers in a CRM. Each bit of data has its personal designated cell.
- Unstructured: That is knowledge and not using a predefined mannequin or group. It contains the textual content inside an electronic mail, a scanned picture of an bill, a prolonged authorized contract, or a buyer assist chat log. There aren’t any neat rows or columns.
- Semi-structured: It is a hybrid. It does not conform to a proper knowledge mannequin however accommodates tags or markers to separate semantic components. A basic instance is an electronic mail, which has structured elements (To, From, Topic traces) however a very unstructured physique.
| Parameter | Structured Information | Unstructured Information | Semi-structured Information |
|---|---|---|---|
| Information Mannequin | – Follows a inflexible schema with rows and columns – Simply saved in relational databases (RDBMS) |
– Lacks predefined format – Seems as emails, photos, movies, and so on. – Requires dynamic storage |
– Identifiable patterns and markers (e.g., tags in XML/JSON) – Doesn’t match into a conventional database construction |
| Information Evaluation | – Simplifies evaluation – Permits easy knowledge mining and reporting |
– Requires advanced methods like NLP and machine studying – Extra effort to interpret |
– Simpler to research than unstructured knowledge – Recognizable tags support in evaluation |
| Searchability | – Extremely searchable with commonplace question languages like SQL – Fast and correct knowledge retrieval |
– Troublesome to look – Wants specialised instruments and superior algorithms |
– Partial group aids in searchability – Metadata and tags may help |
| Visionary Evaluation | – Predictive analytics and pattern evaluation are easy attributable to quantifiable nature | – Wealthy in qualitative insights for visionary evaluation – Requires vital effort to mine |
– Partial group permits some direct visionary evaluation – May have processing for deeper insights |
This spectrum is not simply theoretical; it usually manifests day by day within the type of invoices from a whole lot of various distributors, buy orders in various codecs, and authorized agreements. These paperwork, that are elementary to enterprise operations, are prime examples of the vital, messy, unstructured knowledge that organizations should handle.
The outdated method of “extracting” knowledge was damaged

For years, companies tackled this mess with two main strategies: handbook knowledge entry and conventional Optical Character Recognition (OCR). Guide entry is sluggish, costly, and an ideal recipe for errors like knowledge duplication and inconsistent codecs.
Conventional OCR, the supposed “automated” resolution, was usually worse. These have been inflexible, template-based methods. You’d must create a rule for each single doc structure: “For Vendor A, the bill quantity is all the time on this actual spot.” When Vendor A modified its bill design, the system would break.
However at the moment, these outdated strategies create a a lot deeper drawback. The output of conventional OCR is a “flat blob of textual content.” It strips out all of the vital context. A desk turns into a jumble of phrases, and the connection between a area title (“Whole Quantity”) and its worth (“$5,432.10”) is misplaced.
Feeding this messy, context-free textual content to a Giant Language Mannequin (LLM) is like asking an analyst to make sense of a shredded doc. The AI will get confused, misses connections, and begins to “hallucinate”—inventing details to fill the gaps. This makes the AI untrustworthy and derails your technique earlier than it begins.
The objective: creating LLM-ready knowledge
To construct dependable AI, you want LLM-ready knowledge. This is not only a buzzword; it is a particular technical requirement. At its core, making knowledge LLM-ready entails a number of key steps:
- Cleansing and structuring: The method begins with cleansing the uncooked textual content to take away irrelevant “noise” like headers, footers, or HTML artifacts. The cleaned knowledge is then transformed right into a structured format like Markdown or JSON, which preserves the doc’s unique structure and semantic which means (e.g., “invoice_number”: “INV-123” as a substitute of simply the textual content “INV-123”).
- Chunking: LLMs have a restricted context window, which means they’ll solely course of a certain quantity of data without delay. Chunking is the vital means of breaking down lengthy paperwork into smaller, semantically full items. Good chunking ensures that complete paragraphs or logical sections are stored collectively, preserving context for the AI.
- Embedding and indexing: Every chunk of knowledge is then transformed right into a numerical illustration referred to as an “embedding.” These embeddings are saved in a specialised vector database, creating an listed, searchable data library for the AI.
This complete pipeline—from a messy PDF to a clear, chunked, and listed data base—is what transforms chaotic paperwork into the context-rich gas that high-performance AI fashions require.
The market has responded to this want with quite a lot of instruments. For builders who need to construct customized pipelines, highly effective open-source libraries like Docling, Nanonets OCR-S, Unstructured.io, and LlamaParse present the constructing blocks for parsing and chunking paperwork. On the opposite finish of the spectrum, closed-source platforms from main cloud suppliers like Google (Doc AI), Microsoft (Azure AI Doc Intelligence), and Amazon (Textract) provide managed, end-to-end companies.
Automating vital enterprise paperwork requires extra than simply pace; it additionally calls for enterprise-grade safety. Be sure that the platform you choose affords encryption each in transit and at relaxation, and has a safe infrastructure that gives a centralized, auditable system that mitigates the dangers related to scattered paperwork and handbook processes. As an illustration, Nanonets is totally compliant with stringent world requirements, together with GDPR, SOC 2, and HIPAA, guaranteeing your knowledge is dealt with with the best stage of care.
The Nanonets method: how our AI-powered doc processing solves the issue
That is the issue we’re obsessive about fixing. We use AI to learn and perceive paperwork like a human would, reworking them instantly into LLM-ready knowledge.
The core of our method is what we name AI-powered, template-agnostic OCR. Our fashions are pre-trained on hundreds of thousands of paperwork from around the globe. It does not want inflexible templates as a result of it already understands the idea of an “bill quantity” or a “due date,” no matter its location on the web page. It sees the doc’s structure, understands the relationships between fields, and extracts the data into a superbly structured format.
Because of this you possibly can add invoices from 100 completely different distributors to Nanonets, and it simply works.
💡
Your automated data extraction workflow in 4 easy steps
We’ve designed a whole, end-to-end workflow which you can arrange in minutes. It handles all the pieces from the second a doc arrives to the ultimate export into your system of file.
Step 1: Import paperwork robotically

The primary objective is to cease handbook uploads. You possibly can arrange Nanonets to robotically pull in paperwork from wherever they land. You possibly can auto-forward attachments from an electronic mail inbox (like invoices@yourcompany.com), join a folder in Google Drive, OneDrive, or SharePoint, or combine instantly with our API.
Step 2: Classify, extract, and improve knowledge

As soon as a doc is in, the workflow will get to work. It could first classify the doc sort—for instance, robotically routing invoices to your bill processing mannequin and receipts to your expense mannequin. Then, the AI extracts the related knowledge. But it surely does not cease there. You possibly can add Information Actions to scrub and standardize the data. This implies you are able to do issues like robotically format all dates to YYYY-MM-DD, take away forex symbols from quantities, or cut up a full title into “First Identify” and “Final Identify.”
Step 3: Arrange good approval guidelines
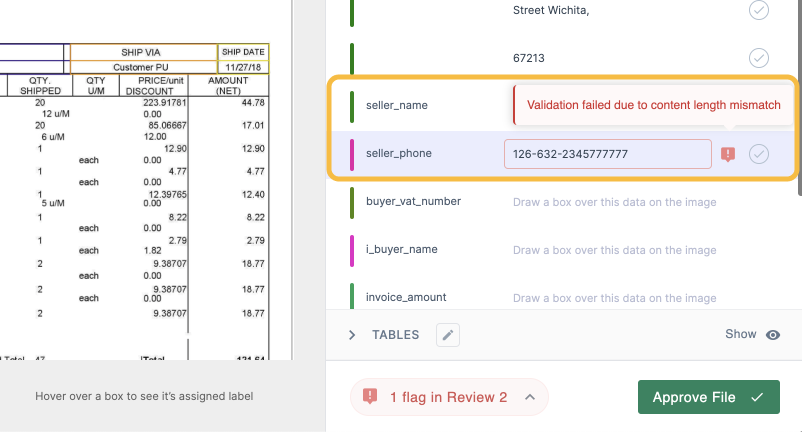
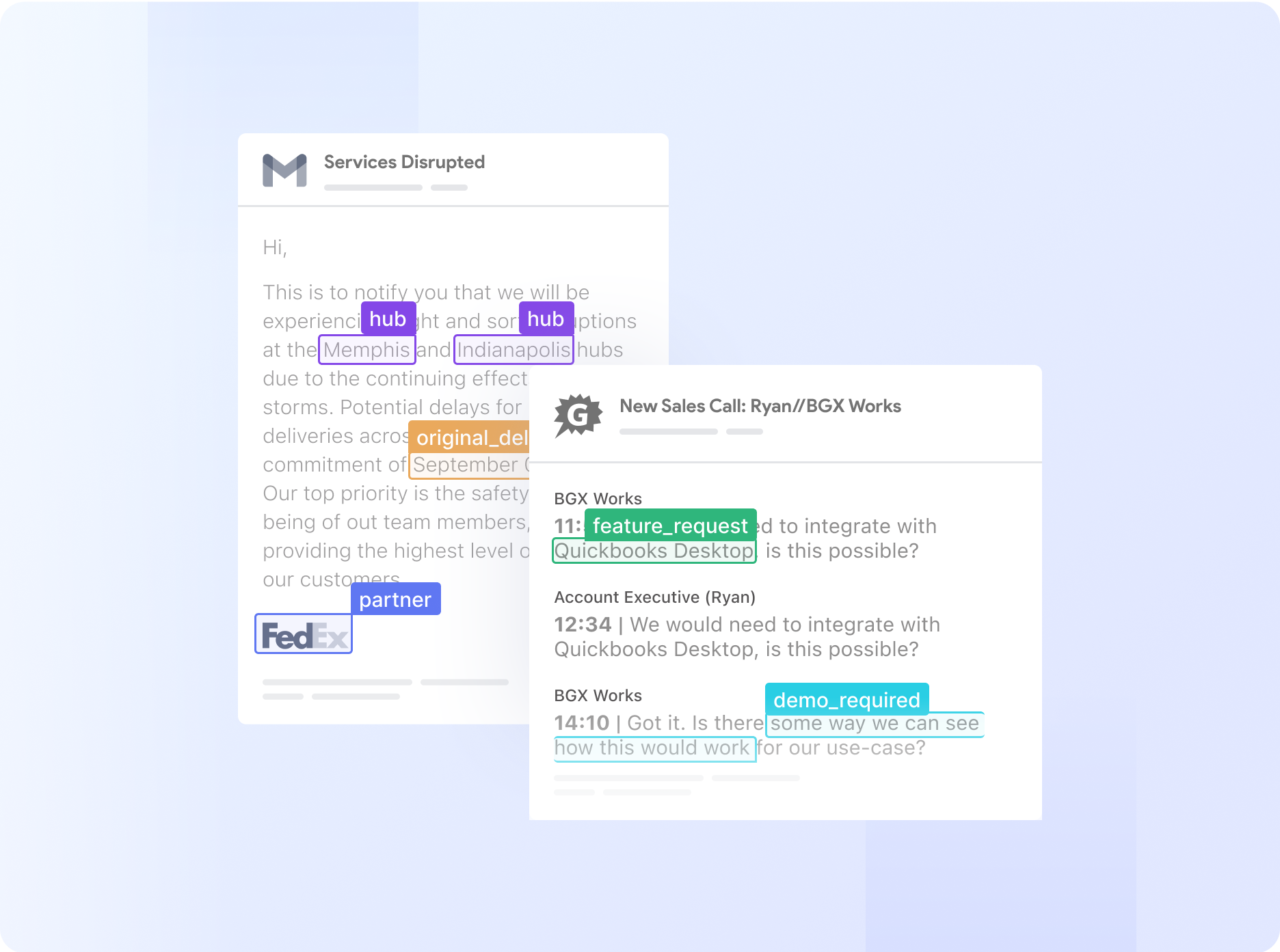
Automation doesn’t suggest giving up management. It means focusing your staff’s consideration the place it is wanted most. You possibly can create easy, highly effective guidelines to handle approvals with out creating bottlenecks. For instance, you possibly can set a rule like, “If the bill whole is over $10,000, flag it for supervisor approval.” Or, a extra superior one: “Examine the PO quantity in opposition to our database; if it doesn’t match, flag it for assessment.” This manner, your staff solely ever has to have a look at the exceptions, not each single doc.
Asian Paints, considered one of Asia’s largest paint firms, makes use of this to handle a community of over 22,000 distributors. Nanonets automates the info extraction from their buy orders, invoices, and supply notes, then flags any discrepancies for the accounts staff instantly inside their SAP system.
Step 4: Export clear knowledge on to your instruments
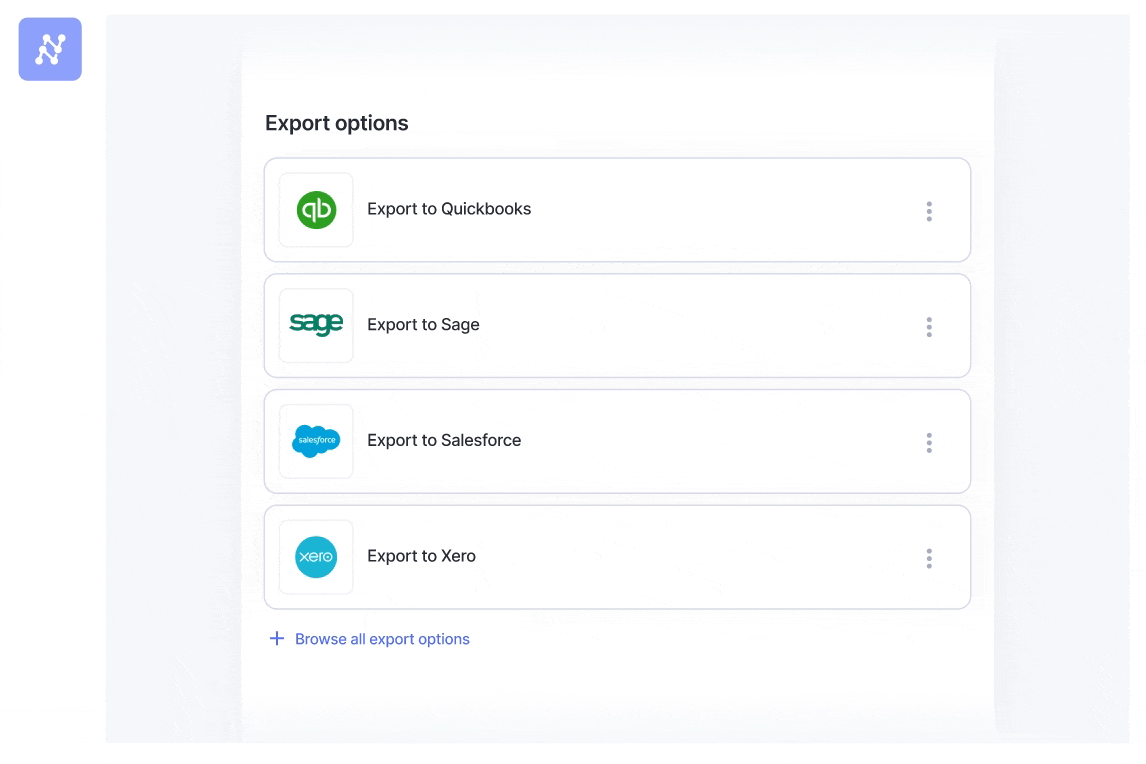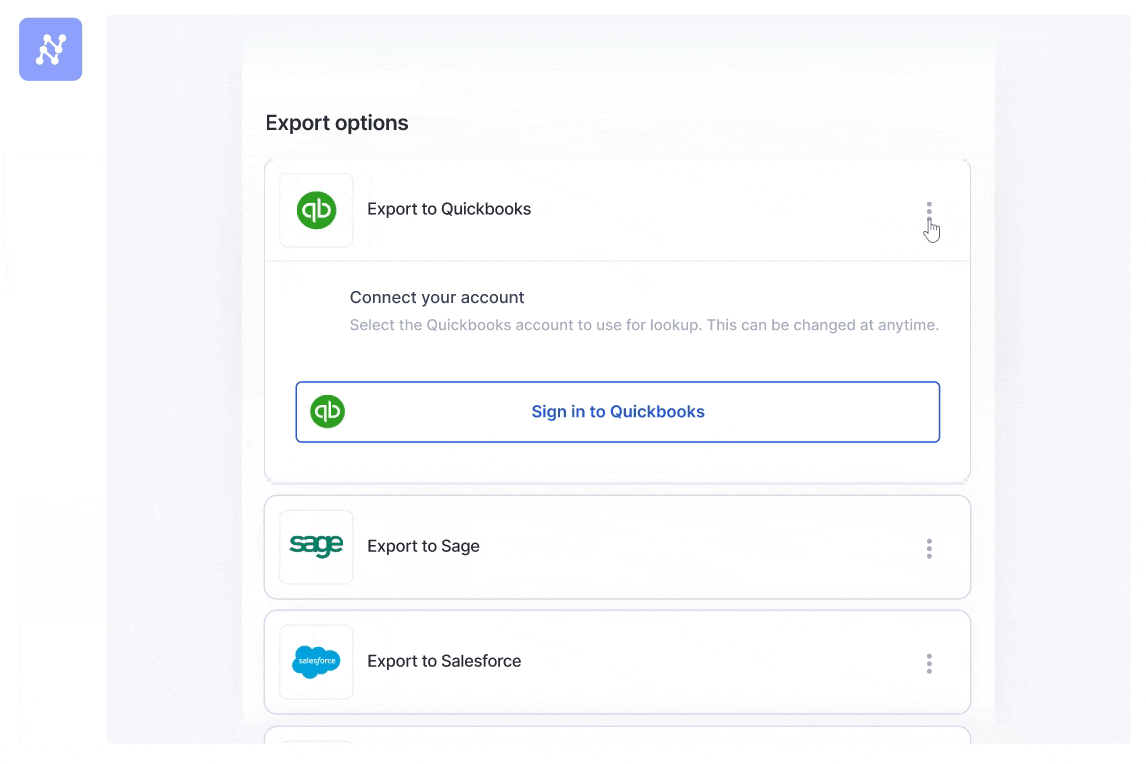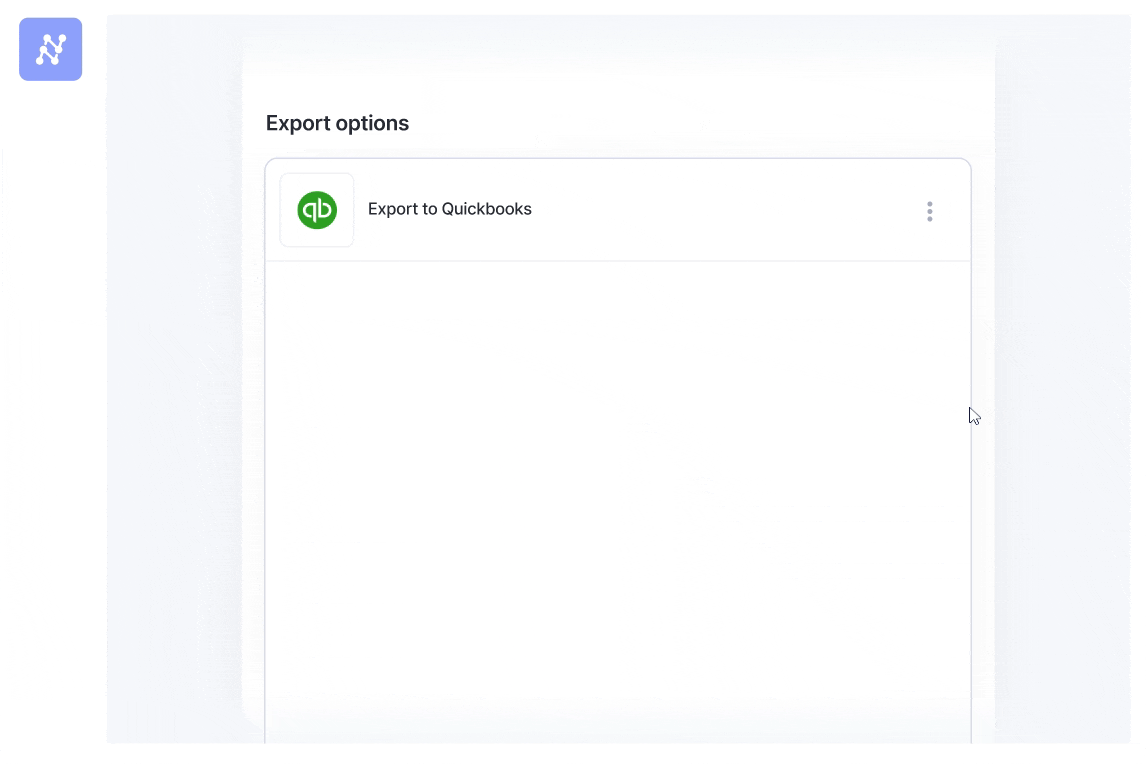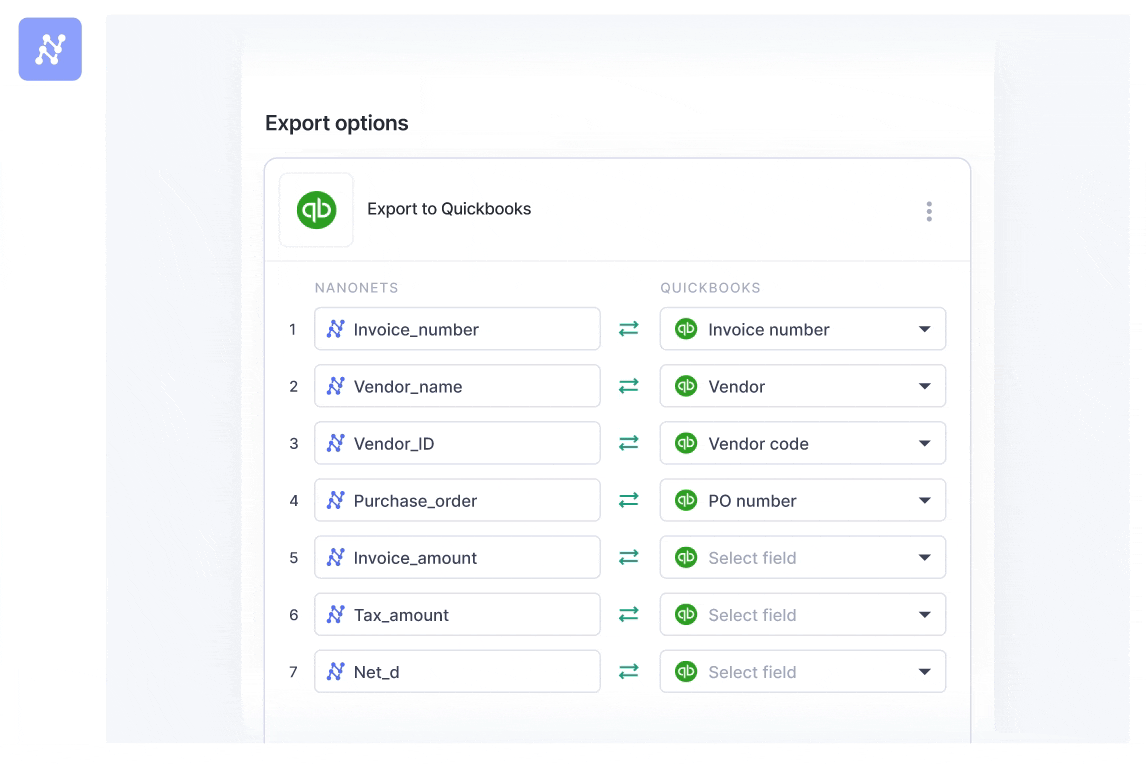
The ultimate step is getting the clear, structured knowledge the place it must go, with out anybody having to elevate a finger. Nanonets has pre-built integrations for standard instruments like QuickBooks, Salesforce, and SAP, in addition to general-purpose exports to LLM purposes, databases or perhaps a easy Google Sheet. The objective is a seamless circulation of data, from unstructured doc to actionable knowledge in your system.
For Augeo, an outsourced accounting agency, this was a game-changer. They use our direct Salesforce integration to automate accounts payable for a consumer processing 3,000 invoices each month. A course of that used to take their staff 4 hours every day now takes lower than half-hour.
Unstructured knowledge extraction in motion
The influence of this know-how is most profound in document-intensive industries. Listed below are a number of examples of how our prospects use clever automation to remodel their operations:
- Banking & finance: Monetary establishments are buried in paperwork like mortgage purposes, monetary statements, and KYC types. We assist them automate the extraction of vital knowledge from these sources, which drastically hastens credit score decision-making, improves compliance checks, and streamlines buyer onboarding.
- Insurance coverage: The insurance coverage claims course of is notoriously paper-heavy. We see corporations utilizing automated doc processing to extract knowledge from declare types, police studies, and medical data. This enables them to confirm data sooner, cut back fraud, and finally speed up declare decision for his or her prospects.
- Healthcare: An estimated 80% of all healthcare knowledge is unstructured, locked away in physicians’ notes, lab studies, and affected person surveys. By extracting and structuring this knowledge, hospitals and analysis organizations can acquire a extra complete understanding of affected person historical past, determine candidates for medical trials extra shortly, and analyze affected person suggestions to enhance care.
- Actual Property: Property administration corporations cope with a relentless circulation of leases, upkeep requests, and vendor contracts. Automating knowledge extraction from these paperwork helps them observe vital dates, handle bills, and keep a transparent, auditable file of their operations.
The enterprise influence of getting extra out of your unstructured knowledge
This is not nearly making a tedious course of extra environment friendly. It is about turning an information legal responsibility right into a strategic asset.
- Monetary influence: While you course of invoices sooner, you possibly can benefit from early fee reductions and eradicate late charges. For Hometown Holdings, a property administration firm, this led to a direct enhance of their Internet Working Revenue of $40,000 yearly.
- Operational scalability: You possibly can deal with 5 occasions the doc quantity with out hiring extra workers. Ascend Properties grew from managing 2,000 to 10,000 properties with out scaling their AP staff, saving them an estimated 80% in processing prices.
- Worker satisfaction: You release good, succesful folks from mind-numbing knowledge entry. As Ken Christiansen, the CEO of Augeo, advised us, it is a “large financial savings in time” that lets his staff deal with extra worthwhile consulting work.
- Future-proof your AI technique: That is the last word payoff. By constructing a pipeline for clear, structured, LLM-ready knowledge, you’re creating the inspiration to leverage the following wave of AI. Your total doc archive turns into a queryable, clever asset able to energy inner chatbots, automated reporting, and superior analytics.
get began
You don’t want a large, six-month implementation challenge to start. You can begin small, see the worth virtually immediately, after which increase from there.
Right here’s start:
- Choose one doc sort that causes essentially the most ache. Invoices are normally an important place to begin.
- Use considered one of our pre-trained fashions for Invoices, Receipts, or Buy Orders to get instantaneous outcomes.
- You possibly can join a free account, add a number of of your personal invoices, and see the extracted knowledge in seconds. There isn’t any advanced setup required.
Able to tame your doc chaos for good? Start your free trial or book a 15-minute call with our staff. We may help you construct a customized workflow on your actual wants.
FAQs
What’s the distinction between rule-based and AI-driven unstructured knowledge extraction?
Rule-based extraction makes use of manually created templates and predefined logic, making it efficient for structured paperwork with constant codecs however rigid when layouts change. It requires fixed handbook updates and struggles with variations.
AI-driven extraction, in contrast, makes use of machine studying and NLP to robotically study patterns from knowledge, dealing with numerous doc layouts with out predefined guidelines. AI options are extra versatile, scalable, and adaptable, enhancing over time by means of coaching. Whereas rule-based methods work properly for repetitive duties with mounted fields (like commonplace invoices), AI excels with advanced, diverse paperwork like contracts and emails which have inconsistent codecs.
How is AI-powered extraction completely different from conventional OCR software program?
Conventional OCR was template-based, which means you needed to manually create a algorithm for each single doc structure. If a vendor modified their bill format, the system would break.
Our method is template-agnostic. We use AI that has been pre-trained on hundreds of thousands of paperwork, so it understands the context of a doc. It is aware of what an “bill quantity” is, no matter the place it seems, which implies you possibly can course of paperwork with 1000’s of various layouts in a single, dependable workflow.
What does it imply for knowledge to be “LLM-ready”?
LLM-ready knowledge is data that has been cleaned, structured, and ready for an AI to grasp successfully. This entails three key steps:
- Cleansing and Structuring: Eradicating irrelevant “noise” and organizing the info right into a clear format like JSON.
- Chunking: Breaking down lengthy paperwork into smaller, logical items that protect context.
- Embedding and Indexing: Changing these chunks into numerical representations that may be searched and analyzed by AI.
How does automating knowledge extraction assist a enterprise financially?
Automating knowledge extraction has a number of direct monetary advantages. It reduces expensive handbook errors, permits firms to seize early fee reductions on invoices, eliminates late fee charges, and allows companies to deal with a a lot greater quantity of paperwork with out growing headcount.
Is unstructured knowledge extraction scalable for giant datasets?
Sure, unstructured knowledge extraction can successfully scale to deal with giant datasets when carried out with the best applied sciences. Fashionable AI-based extraction methods use deep studying fashions (CNNs, RNNs, transformers) that course of huge quantities of advanced knowledge effectively.
Scalability is additional enhanced by means of cloud computing platforms like AWS and Google Cloud, which offer elastic assets that develop together with your wants. Large knowledge frameworks corresponding to Apache Spark distribute processing throughout machine clusters, whereas parallel processing capabilities allow simultaneous knowledge dealing with.
Organizations can enhance efficiency by implementing batch processing for giant volumes, utilizing pre-trained fashions to scale back computational prices, and adopting incremental studying approaches. With correct infrastructure and optimization methods, these methods can effectively course of terabytes and even petabytes of unstructured knowledge.
Do I would like a staff of builders to begin automating knowledge extraction from unstructured paperwork?
No. Whereas builders can use APIs to construct customized options, trendy platforms are designed with no-code interfaces. This enables enterprise customers to arrange automated workflows, use pre-trained fashions for widespread paperwork like invoices, and combine with different enterprise software program with out writing any code.