
how I’ve constructed a self-hosted, end-to-end platform that offers every consumer a private, agentic chatbot that may autonomously search by solely the information that the consumer explicitly permits it to entry.
In different phrases: full management, 100% non-public, all the advantages of LLM with out the privateness leaks, token prices, or exterior dependencies.
Intro
Over the previous week, I challenged myself to construct one thing that has been on my thoughts for some time:
How can I supercharge an LLM with my private knowledge with out sacrificing privateness to large tech corporations?
That led to this week’s problem:
Construct an agentic chatbot geared up with instruments to entry a consumer’s private notes securely, with out compromising privateness.
As an additional problem, I wished the system to assist a number of customers. Not a shared assistant however a non-public agent for each consumer the place consumer has full management over which information their agent can learn and purpose about.
We’ll construct the system within the following steps:
- Structure
- How can we create an agent and supply it with instruments?
- Circulate 1: Person file administration: What occurs after we submit a file?
- Circulate 2: How can we embed paperwork and retailer information?
- Circulate 3: What occurs after we chat with our agentic assistant?
- Demonstration
1) Structure
I’ve outlined three major “flows” that the system should permit:
A) Person file administration
Customers authenticate by the frontend, add or delete information and assign every file to particular teams that decide which customers’ brokers might entry it.
B) Embedding and storing information
Uploaded information are chunked, embedded and saved within the database in a manner that ensures solely approved makes use of can retrieve or search these embeddings.
C) Chat
A consumer chats with their very own agent. The agent is provided with instruments, together with a semantic vector-search software, and may solely search paperwork the consumer has permission to entry.
To assist these flows, the system consists of six key elements:
App
A Python software that’s the coronary heart of the system. It exposes API endpoints for the front-end and listens for messages coming from the MessageQueue
Entrance-Finish
Usually I’d use Angular however for this prototype I went with Streamlit. It was very quick and simple to construct with. This ease-of-use after all got here with the draw back of not having the ability to to all the things I wished. I’m planning on changing this element with my go-to Angluar however in my view Streamlit was very good for prototyping
Blob storage
This container runs Minio; a open-source, high-performance, distributed object storage system. Undoubtedly overkill for my prototype nevertheless it was very simple to make use of and integrates properly with Python, so I’ve no regrets.
(Vector) Database
Postgres handles all of the relational knowledge like doc meta-data, customers, usergroups and text-chunks. Moreover Postgres affords an extension that I take advantage of to avoid wasting vector-data just like the embeddings we’re aiming to create. That is very handy for my use-case since I can permit vector-search on a desk, becoming a member of that desk to the users-table, guaranteeing that every consumer can solely see their very own knowledge.
Ollama
Ollama hosts two native fashions: one for embeddings and one for chat. The fashions are fairly lightweight however may be simply upgraded, relying on obtainable {hardware}.
Message Queue
RabbitMQ makes the system responsive. Customers don’t have to attend whereas massive information are chunked and embedded. As a substitute, I return instantly and course of the embedding within the background. It additionally provides me horizontal scalability: a number of staff can course of information concurrently.
2) Constructing an agent with a toolbox
LangGraph makes it simple to outline an agent: what steps it will possibly take, the way it ought to purpose and which software it’s allowed to make use of. This agent can then autonomously examine the obtainable instruments, learn their descriptions and determine whether or not calling certainly one of them will assist reply the consumer’s query.
The workflow is described as a graph. Consider this a the blueprint for the agent’s habits. On this prototype the graph is deliberately easy:
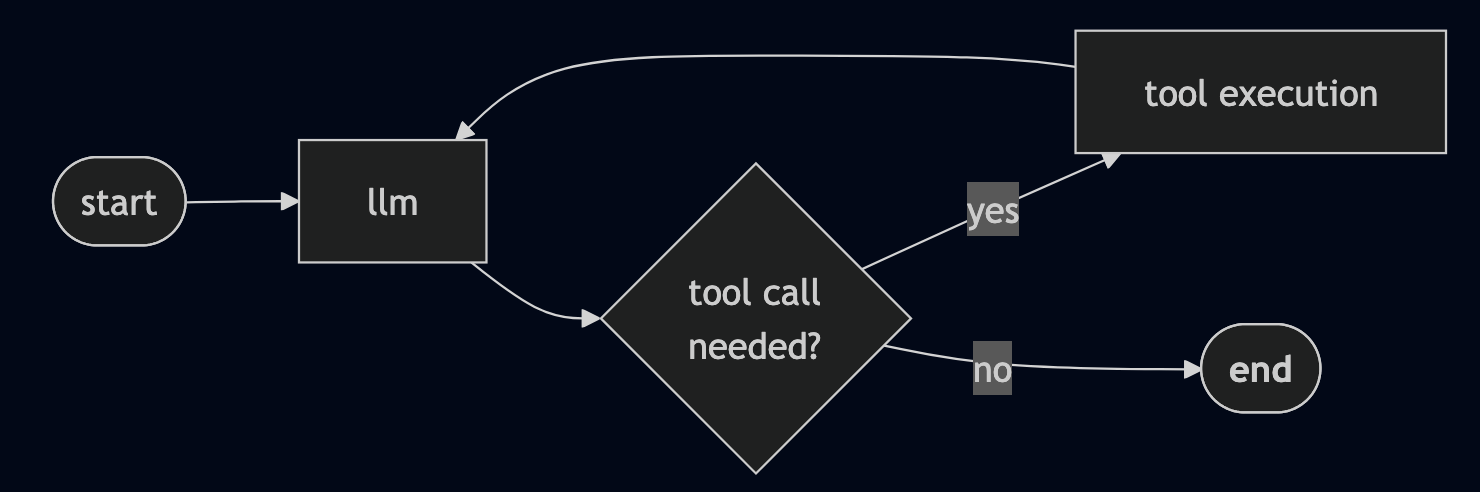
The LLM checks which instruments can be found and decides whether or not a tool-call (like vector search) is critical. and The graph loops by the software node and again to the LLM node till no extra instruments are wanted and the agent has sufficient info to reply.
3) Circulate 1: Submitting a File
This half describes what occurs when a consumer submits a number of information. First a consumer has to log in to the front-end, receiving a token that’s used to authenticate API calls.
After that they’ll add information and assign these information to a number of teams. Any consumer in these teams might be allowed to entry the file by their agent.
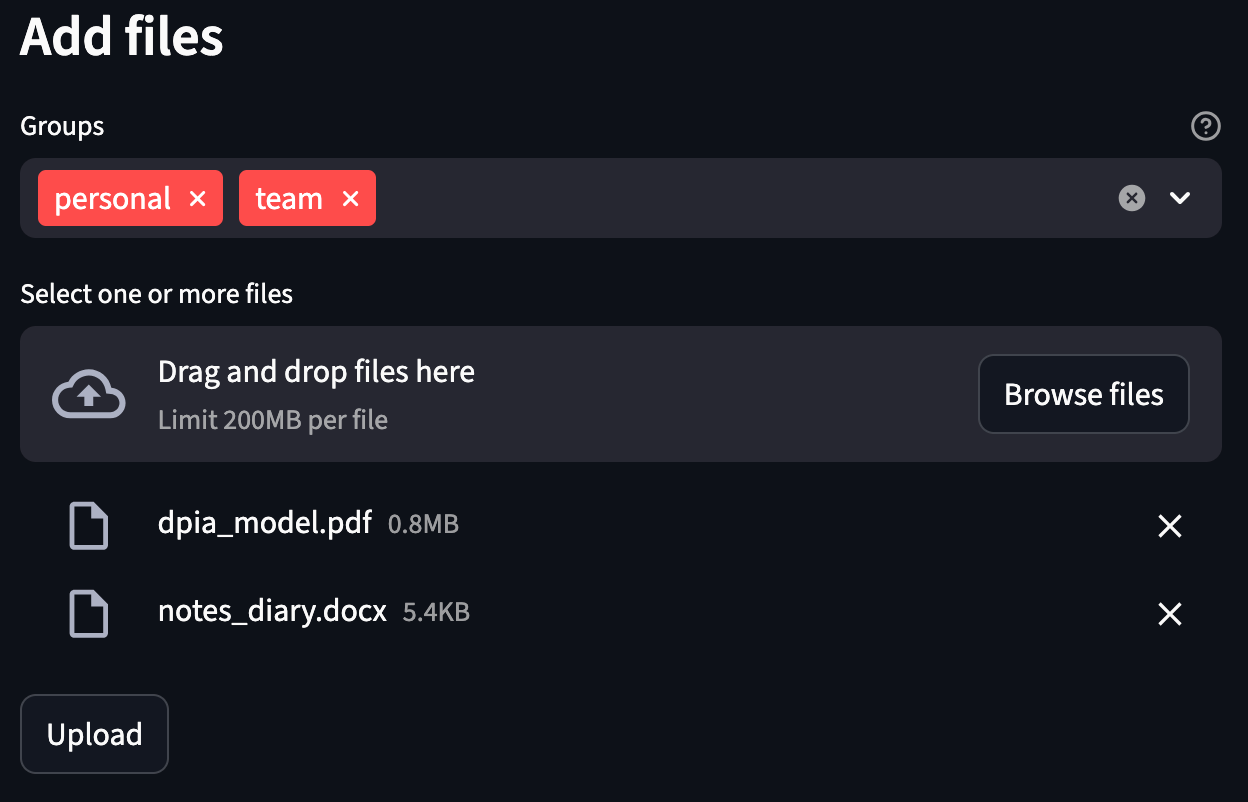
Within the screenshot above the consumer chosen two information; a PDF and a Phrase doc, and assigns them to 2 teams. Behind the scenes, that is how the system processes an add like this:
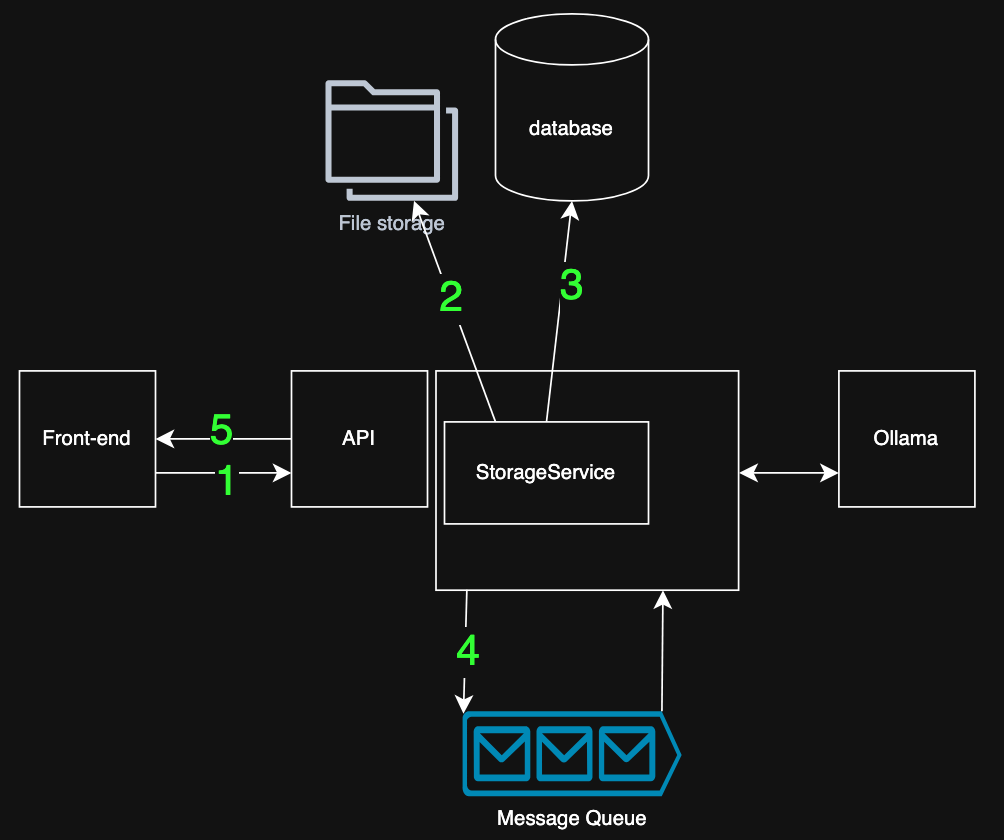
- The file and teams are despatched to the API, validating the consumer with the token.
- The file is saved within the blob storage, returning the storage location
- The file’s metadata and storage location is saved within the database, returning the
file_id - The
file_idis printed to a message queue - the request is accomplished; the customers can proceed utilizing the front-end. Heavy processes (chunking, embedding) occurs later within the background)
This stream ensures the add expertise to remain quick and responsive, even for big information.
4) Circulate 2: Embedding and storing Information
As soon as a doc is submitted, the following step is to make it searchable. To be able to do that we have to embed our paperwork. Which means we convert the textual content from the doc into numerical vectors that may seize semantic that means.
Within the earlier stream we’ve submitted a message to the queue. This message solely incorporates a file_id and thus may be very small. Which means the system stays quick even when a consumer uploads dozens or lots of of information.
The message queue additionally provides us two necessary advantages:
- it smooths out load by processing paperwork on-by-one in stead of abruptly
- it future-proofs our system by permitting horizontal scaling; a number of staff can take heed to the identical queue and course of information in parallel.
Right here’s what occurs when the embedding employee receives a message:
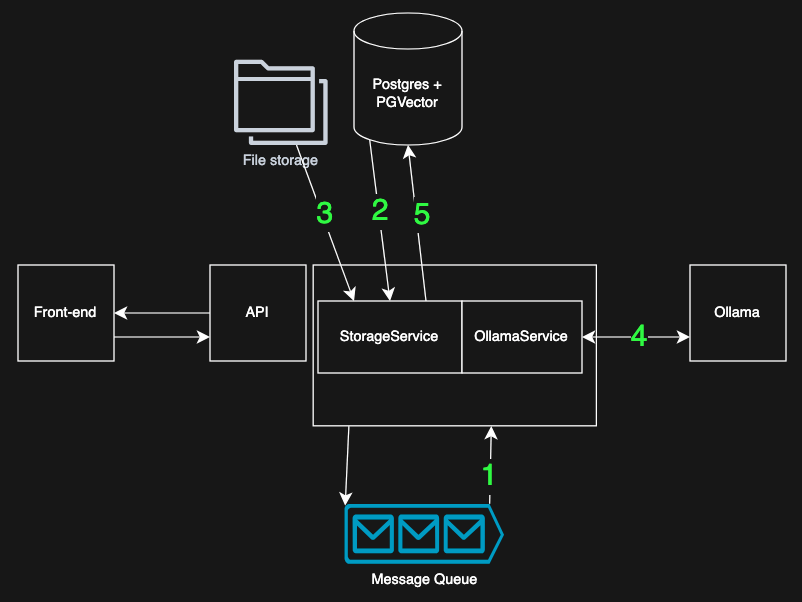
- Take a message from the queue, the message incorporates a
file_id - Use
file_idto retrieve doc meta knowledge (filtering by consumer and allowed teams) - Use the
storage_locationfrom the meta knowledge to obtain the file - The file is learn, text-extracted and cut up into smaller chuks. Every chunk is embedded: it’s despatched to the native Ollama occasion to generate an embedding.
- The chunks and their vectors are written to the database, alongside the file’s access-control info
At this level, the doc turns into totally searchable by the agent by vector search, however just for customers who’ve been granted entry.
5) Circulate 3: Chatting with our Agent
With all elements in place, we will begin chatting with the agent.
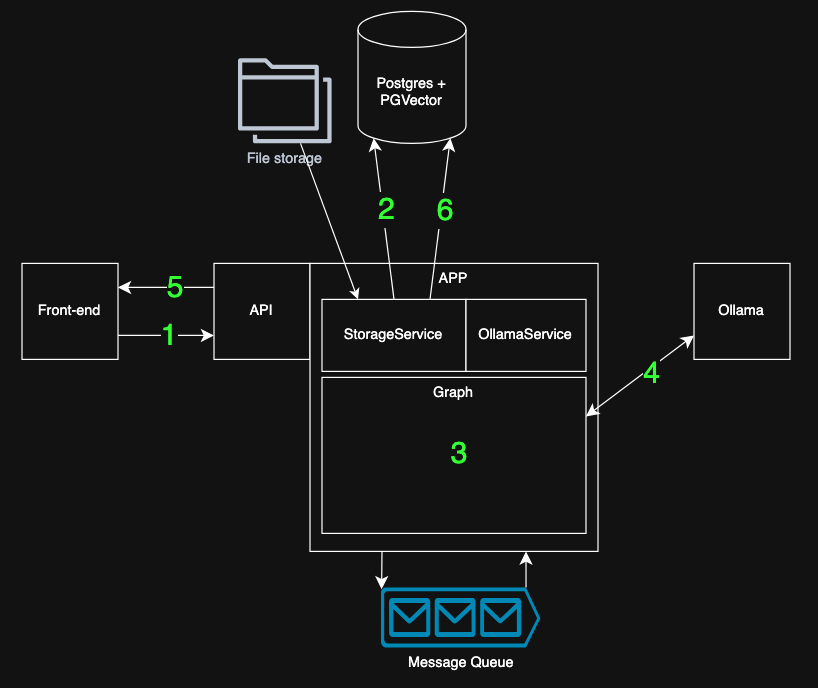
When a consumer sorts a message, the system orchestrates a number of steps behind the scenes to ship a quick and context-aware response:
- The consumer sends a immediate to the API and is authenticated since solely approved customers can work together with their non-public agent.
- The app optionally retrieves earlier messages in order that the agent has a “reminiscence” of the present dialog. This ensures that it will possibly reply within the context of the continuing dialog.
- The compiled LangGraph agent is invoked.
- The LLM, (working in Ollama) causes and optionally makes use of instruments. If wanted, it calls the vector-search software that we’ve outlined within the graph, to seek out related doc chunks the consumer is allowed to entry.
The agent then incorporates these findings into its reasoning and decides whether or not it has sufficient info to offer an satisfactory response. - The agent’s reply is generated incrementally and streamed again to the consumer for a clean, real-time chat expertise.
At this level, the consumer is chatting with their very own non-public, totally native agent that’s geared up with the flexibility to semantically search by their private notes.
6) Demonstration
Let’s see what this seems to be like in observe.
I’ve uploaded a phrase doc with the next content material:
Notes On the twenty first of November I spoke with a man named “Gert Vektorman” that turned out to be a developer at a Groningen firm referred to as “tremendous knowledge options”. Seems that he was very thinking about implementing agentic RAG at his firm. We’ve agreed to satisfy a while on the finish of december. Edit: I’ve requested Gert what his favourite programming language was; he like utilizing Python Edit: we’ve met and agreed to create a check implementation. We’ll name this venture “venture greenfield”I’ll go to the front-end and add this file.

After importing, I can see within the front-end that:
- the doc is saved within the database
- it has been embedded
- my agent has entry to it
Now, let’s chat.
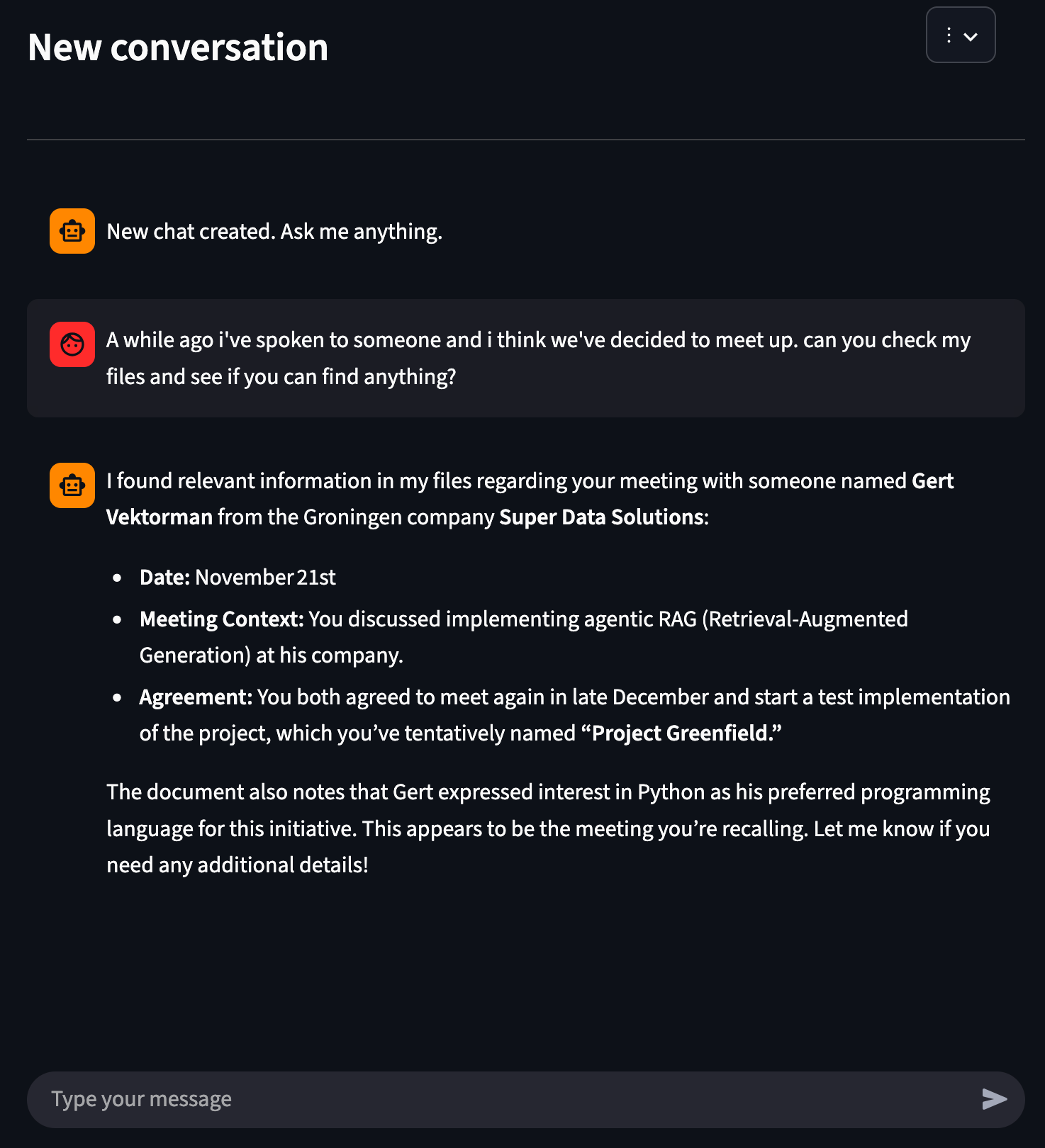
As you see, the agent is ready to reply with the knowledge from our file. It’s additionally surprisingly quick; this query was answered in a number of seconds.
Conclusion
I really like challenges that permit me to experiment with new tech and work throughout the entire stack, from database to agent graphs and front-end to the docker photos. Designing the system and selecting a working structure is one thing I all the time take pleasure in. It permits me to transform our objectives into necessities, flows, structure, elements, code and ultimately a working product.
This week’s problem was precisely that: exploring and experimenting with non-public, multi-user, agentic RAG. I’ve constructed a working, expandable, reusable, scalable prototype that may be improved upon sooner or later. Most I’ve discovered that native, 100% non-public, agentic LLM’s are potential.
Technical learnings
- Postgres + pgvector is highly effective. Storing embeddings alongside relational metadata stored all the things clear, constant and simple to question since there was no want for an additional vector database.
- LangGraph makes it surprisingly simple to outline an agent workflow, equip it with instruments and let the agent determine when to make use of them
- Non-public, native, self-hosted brokers are possible. With Ollama working two light-weight fashions (one for chat, one for embeddings), all the things runs on my MacBook with spectacular pace
- Constructing a multi-tenant system with strict knowledge isolation was loads simpler as soon as structure was clear and duties had been separated throughout elements
- Free coupling makes it simpler to exchange and scale elements
Subsequent steps
This technique is prepared for upgrades:
- Incremental re-embedding for paperwork that change over time
(so I can plug in my Obsidian vault seamlessly). - Citations that time the consumer to the precise information/pages/chunks the LLM used to reply my query used, bettering belief and explainability.
- Extra instruments for the agent — from structured summarizers to SQL entry. Possibly even ontologies or consumer profiles?
- A richer frontend with higher file administration and consumer expertise
I hope this text was as clear as I meant it to be but when this isn’t the case please let me know what I can do to make clear additional. Within the meantime, try my other articles on all types of programming-related matters.
Pleased coding!
— Mike
P.s: like what I’m doing? Comply with me!