
Introduction
the the cutting-edge structure for NLP and never solely. Trendy fashions like ChatGPT, Llama, and Gemma are based mostly on this structure launched in 2017 within the Consideration Is All You Want paper from Vaswani et al.
Within the previous article, we noticed how you can use spaCy to perform a number of duties, and also you might need observed that we by no means needed to practice something, however we leveraged spaCy capabilities, that are primarily rule-based approaches.
SpaCy additionally provides to insert within the NLP pipeline trainable parts or to make use of fashions off the shelf from the 🤗 HuggingFace Hub, which is a web-based platform that gives open-source fashions for AI builders to make use of.
So let’s discover ways to use SpaCy with Hugging Face’s fashions!
Why Transformers?
Earlier than transformers the SOTA structure to create vector representations of phrases was phrase vectors methods. A phrase vector is a dense illustration of a phrase, which we are able to use to carry out some mathematical calculation on it.
For instance, we are able to observe that two phrases which have the same which means even have comparable vectors. Probably the most well-known methods of this type are GloVe and FastText.
These strategies, although, have launched a giant downside, a phrase is represented all the time by the identical vector. However a phrase doesn’t all the time have the identical which means.
For instance:
- “She went to the financial institution to withdraw some cash.”
- “He sat by the financial institution of the river, watching the water circulate.”
In these two sentences, the phrase financial institution assumes two totally different meanings, so it doesn’t make sense to all the time signify the phrase with the identical vector.
With transformer-based structure, we’re ready in the present day to create fashions that think about the whole context to generate the vectorial illustration of a phrase.
The primary innovation launched by this community is the multi-head consideration block. In case you are not aware of it, I lately wrote an article about this: https://towardsdatascience.com/a-simple-implementation-of-the-attention-mechanism-from-scratch/
The transformer is made up of two components. The left half, which is the encoder which creates the vectorial illustration of texts, and the precise half, the decoder, is used to generate new textual content. For instance, GPT relies on the precise half, as a result of it generates textual content as a chatbot.
On this article, we have an interest within the encoder half, which is ready to seize the semantics of the textual content we give as enter.
BERT and RoBERTa
This gained’t be a course about these fashions, however let’s recap some principal subjects.
Whereas ChatGPT is constructed on the decoder aspect of the transformer structure, BERT and RoBERTa are based mostly on the encoder aspect.
BERT was launched by Google in 2018 and you may learn extra about it right here: https://arxiv.org/abs/1810.04805
BERT is a stack of encoder layers. There are two sizes of this mannequin. BERT base accommodates 12 encoders whereas BERT giant accommodates 24 encoders

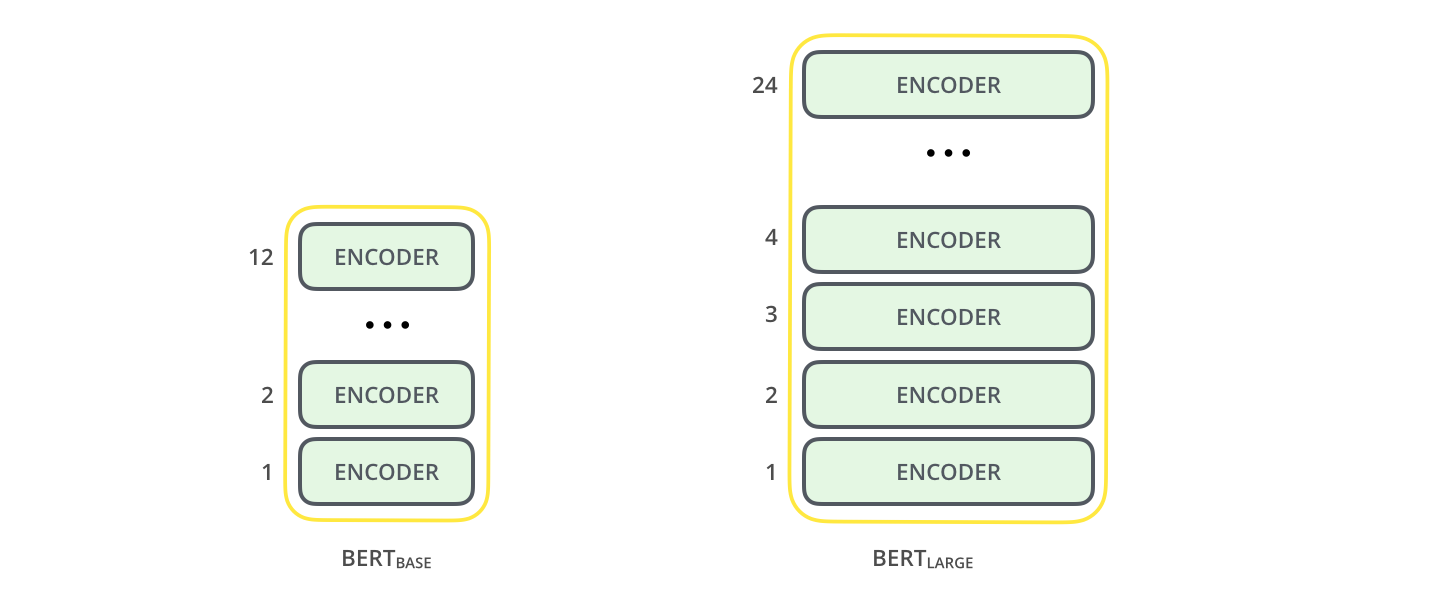{kind=link}
BERT base generates a vector of dimension 768, whereas the big one a vector of dimension 1024. Each take an enter of dimension 512 tokens.
The tokenizer utilized by the BERT mannequin is known as WordPiece.
BERT is educated on two goals:
- Masked Language Modeling (MLM): Predicts lacking (masked) tokens inside a sentence.
- Subsequent Sentence Prediction (NSP): Determines whether or not a given second sentence logically follows the primary one.
RoBERTa mannequin builds on prime of BERT with some key variations: https://arxiv.org/abs/1907.11692.
RoBERTa makes use of a dynamic masking, so masked tokens change at each iteration through the coaching, and doesn’t use the NSP as coaching goals.
Use RoBERTa with SpaCy
The TextCategorizer is a spaCy part that predicts a number of labels for a whole doc. It might probably work in two modalities:
- exclusive_classes = true: one label per textual content (e.g., constructive or unfavourable)
- exclusive_classes = false: a number of labels per textual content (e.g., spam, pressing, billing)
spaCy can mix this with totally different embeddings:
- Traditional phrase vectors (
tok2vec) - Transformer fashions like RoBERTa, which we use right here
On this means we are able to lavarage the RoBERTa understanding of the english language, and combine it within the spacy pipeline to make it manufacturing prepared.
In case you have a dataset, you possibly can additional practice the RoBERTa mannequin utilizing spaCy to fine-tune it on the particular downstream job you’re making an attempt to resolve.
Dataset preparation
On this article I’m going to make use of the TREC dataset, which accommodates quick questions. Every query is labelled with the kind of reply it expects, corresponding to:
| Label | Which means |
|---|---|
| ABBR | Abbreviation |
| DESC | Description / Definition |
| ENTY | Entity (factor, object) |
| HUM | Human (particular person, group) |
| LOC | Location (place) |
| NUM | Numeric (depend, date, and so on) |
That is an instance, the place we count on as reply a human identify:
Q (textual content): “Who wrote the Iliad?”
A (label): “HUM”
As ordinary we begin by putting in the libraries.
!pip set up datasets==3.6.0
!pip set up -U spacy[transformers]Now we have to load put together the dataset.
With spacy.clean("en") we are able to create a clean spaCy pipeline for English. It doesn’t embody any parts (just like the tagger or the parser),. It’s light-weight and ideal for changing uncooked textual content to Doc objects with out loading a full language mannequin like we do with en_core_web_sm.
DocBin is a particular spaCy class that effectively shops many Doc objects in binary format. That is how spaCy expects coaching knowledge to be saved.
As soon as transformed and saved as .spacy recordsdata, these might be handed straight into spacy practice, which is way sooner than utilizing plain JSON or textual content recordsdata.
So now this script to organize the practice and dev dataset needs to be fairly simple.
from datasets import load_dataset
import spacy
from spacy.tokens import DocBin
# Load TREC dataset
dataset = load_dataset("trec")
# Get label names (e.g., ["DESC", "ENTY", "ABBR", ...])
label_names = dataset["train"].options["coarse_label"].names
# Create a clean English pipeline (no parts but)
nlp = spacy.clean("en")
# Convert Hugging Face examples into spaCy Docs and save as .spacy file
def convert_to_spacy(break up, filename):
doc_bin = DocBin()
for instance in break up:
textual content = instance["text"]
label = label_names[example["coarse_label"]]
cats = {identify: 0.0 for identify in label_names}
cats[label] = 1.0
doc = nlp.make_doc(textual content)
doc.cats = cats
doc_bin.add(doc)
doc_bin.to_disk(filename)
convert_to_spacy(dataset["train"], "practice.spacy")
convert_to_spacy(dataset["test"], "dev.spacy")
We’re going to firther practice RoBERTa on this dataset utilizing a sapCy CLI command. The command expects a config.cfg file the place we describe the kind of coaching, the mannequin we’re utilizing, the variety of epohchs and so on.
Right here is the config file I used for my coaching pourposes.
[paths]
practice = ./practice.spacy
dev = ./dev.spacy
vectors = null
init_tok2vec = null
[system]
gpu_allocator = "pytorch"
seed = 42
[nlp]
lang = "en"
pipeline = ["transformer", "textcat"]
batch_size = 32
[components]
[components.transformer]
manufacturing unit = "transformer"
[components.transformer.model]
@architectures = "spacy-transformers.TransformerModel.v3"
identify = "roberta-base"
tokenizer_config = {"use_fast": true}
transformer_config = {}
mixed_precision = false
grad_scaler_config = {}
[components.transformer.model.get_spans]
@span_getters = "spacy-transformers.strided_spans.v1"
window = 128
stride = 96
[components.textcat]
manufacturing unit = "textcat"
scorer = {"@scorers": "spacy.textcat_scorer.v2"}
threshold = 0.5
[components.textcat.model]
@architectures = "spacy.TextCatEnsemble.v2"
nO = null
[components.textcat.model.linear_model]
@architectures = "spacy.TextCatBOW.v3"
ngram_size = 1
no_output_layer = true
exclusive_classes = true
size = 262144
[components.textcat.model.tok2vec]
@architectures = "spacy-transformers.TransformerListener.v1"
upstream = "transformer"
pooling = {"@layers": "reduce_mean.v1"}
grad_factor = 1.0
[corpora]
[corpora.train]
@readers = "spacy.Corpus.v1"
path = ${paths.practice}
[corpora.dev]
@readers = "spacy.Corpus.v1"
path = ${paths.dev}
[training]
train_corpus = "corpora.practice"
dev_corpus = "corpora.dev"
seed = ${system.seed}
gpu_allocator = ${system.gpu_allocator}
dropout = 0.1
accumulate_gradient = 1
persistence = 1600
max_epochs = 10
max_steps = 2000
eval_frequency = 100
frozen_components = []
annotating_components = []
[training.optimizer]
@optimizers = "Adam.v1"
learn_rate = 0.00005
L2 = 0.01
grad_clip = 1.0
use_averages = false
eps = 1e-08
beta1 = 0.9
beta2 = 0.999
L2_is_weight_decay = true
[training.batcher]
@batchers = "spacy.batch_by_words.v1"
discard_oversize = false
tolerance = 0.2
[training.batcher.size]
@schedules = "compounding.v1"
begin = 256
cease = 2048
compound = 1.001
[training.logger]
@loggers = "spacy.ConsoleLogger.v1"
progress_bar = true
[training.score_weights]
cats_score = 1.0
[initialize]
vectors = ${paths.vectors}
init_tok2vec = ${paths.init_tok2vec}
vocab_data = null
lookups = null
[initialize.components]
[initialize.tokenizer]
Be sure to have a GPU at your disposal and launch the coaching CLI command!
python —m spacy practice config.cfg --output ./output --gpu-id 0
You will note the coaching beginning with and you may monitor the lack of the TextCategorizer part.

Simply to be clear, we’re coaching right here the TextCategorizer part, which is a small neural community head that receives the doc illustration and learns to foretell the proper label.
However we’re additionally fine-tuning RoBERTa throughout this coaching. Which means the RoBERTa weights are up to date utilizing the TREC dataset, so it learns how you can signify enter questions in a means that’s extra helpful for classification.
As soon as the mannequin is educated and saved, we are able to use it in inference!
import spacy
nlp = spacy.load("output/model-best")
doc = nlp("What's the capital of Italy?")
print(doc.cats)
The output needs to be one thing just like the next
{'LOC': 0.98, 'HUM': 0.01, 'NUM': 0.0, …}
Last Ideas
To recap, on this publish we noticed how you can:Use a Hugging Face dataset with spaCy
- Convert textual content classification knowledge into
.spacyformat - Configure a full pipeline utilizing RoBERTa and
textcat - Practice and check your mannequin utilizing spaCy CLI
This technique works for any quick textual content classification job, emails, assist tickets, product opinions, FAQs, and even chatbot intents.