 Can Trick You: A Field Guide to Paradoxes")
Overview
simply optical illusions or mind-bending puzzles. They can be logical, inflicting preliminary observations to crumble upon nearer investigation. In knowledge science, paradoxes come up once we take numbers at face worth, with out wanting into the context behind them. One can have the sharpest visuals and nonetheless stroll away with the fallacious story.
On this article, we talk about three logical paradoxes that function cautionary tales for anybody who interprets knowledge too shortly, with out making use of context. We discover how paradoxes come up in Information Science & Enterprise Intelligence (BI) use instances after which lengthen the insights to Retrieval-Augmented Era (RAG) programs, the place related paradoxes can undermine the standard of each the immediate supplied and the mannequin’s output.
Simpson’s Paradox in Enterprise Intelligence
Simpson’s paradox describes the situation the place developments reverse when knowledge is aggregated. In different phrases, the developments that you simply observe in subgroups get flipped while you mix the numbers and analyze them. Let’s assume that we’re analyzing the gross sales of 4 areas of a well-liked Ice cream chain. When the gross sales for every location are individually analyzed, it means that the chocolate taste is essentially the most most popular amongst clients. However when the gross sales are added up, the development goes away, and the brand new mixed outcomes recommend that vanilla is most popular essentially the most. This development reversal is denoted by Simpson’s Paradox. We use the fictional knowledge beneath to show this.
| Location | Chocolate | Vanilla | Complete Clients | Chocolate % | Vanilla % | Winner |
| Suburb A | 15 | 5 | 20 | 75.0% | 25.0% | Chocolate |
| Metropolis B | 33 | 27 | 60 | 55.0% | 45.0% | Chocolate |
| Mall | 2080 | 1920 | 4000 | 52.0% | 48.0% | Chocolate |
| Airport | 1440 | 2160 | 3600 | 40.0% | 60.0% | Vanilla |
| Complete | 3568 | 4112 | 7680 | 46.5% | 53.5% | Vanilla! |
Under is a visible illustration.
An information analyst who overlooks these subgroup dynamics could assume that chocolate is underperforming. Therefore, it’s important to combination numbers by subgroups and verify for the presence of Simpson’s paradox. When a reversal in development happens, the lurking variable ought to be recognized as the subsequent step. A lurking variable is the hidden issue influencing group outcomes. On this case, the shop location occurs to be the lurking variable. A deep contextual understanding is required to interpret why the sale of vanilla icecreams was excessive on the airport, flipping the general end result. Some questions that might be used to research are:
• Do airport retailers inventory fewer chocolate choices?
• Do vacationers want milder flavors?
• Was there a promotional marketing campaign favoring Vanilla at shops within the airport?
Simpson’s Paradox in RAG Programs
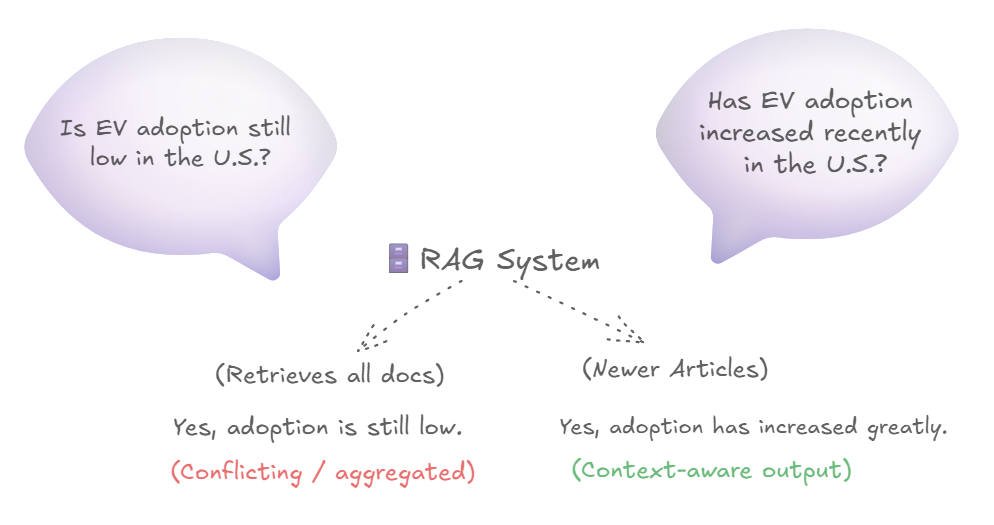
Let’s suppose that you’ve an RAG (Retrieval-Augmented Era) mannequin that gauges public sentiment in the direction of electrical autos (EVs) and solutions questions across the similar. The mannequin makes use of information articles from 2010 to 2024. Till 2016, EVs had been receiving blended opinions on account of their restricted vary, larger shopping for value, and lack of charging stations. All these elements made driving in EVs for lengthy distances unimaginable. Newspaper stories earlier than 2017 used to spotlight such deficiencies. However as of 2017, EVs began being perceived in an excellent gentle on account of enhancements in efficiency and the provision of charging stations. This shift in notion occurred notably after the profitable launch of Tesla’s premium EV. An RAG mannequin that makes use of information stories from 2010 to 2024 would most likely give contradictory responses to related questions, which can set off the Simpson’s Paradox.
For instance, if the RAG is requested, “Is EV adoption within the US nonetheless low?”, the reply could be “Sure, adoption stays low on account of excessive shopping for prices and restricted infrastructure”. If the RAG is requested, “Has EV adoption elevated lately within the U.S.?”, the reply can be ‘Sure, adoption has elevated vastly on account of developments in know-how and charging infrastructure’. On this case, the lurking variable is the publication date. A sensible repair to this problem is to tag paperwork (articles) into time-based bins through the pre-processing section. Different choices embrace encouraging the customers to specify a time vary of their immediate (e.g. Within the final 5 years, how has the adoption of EV been?) or fine-tuning the LLM to explicitly state the timeline that it’s contemplating for its response (e.g., Round 2024, EV Adoption has elevated vastly.).
Accuracy Paradox in Information Science Issues
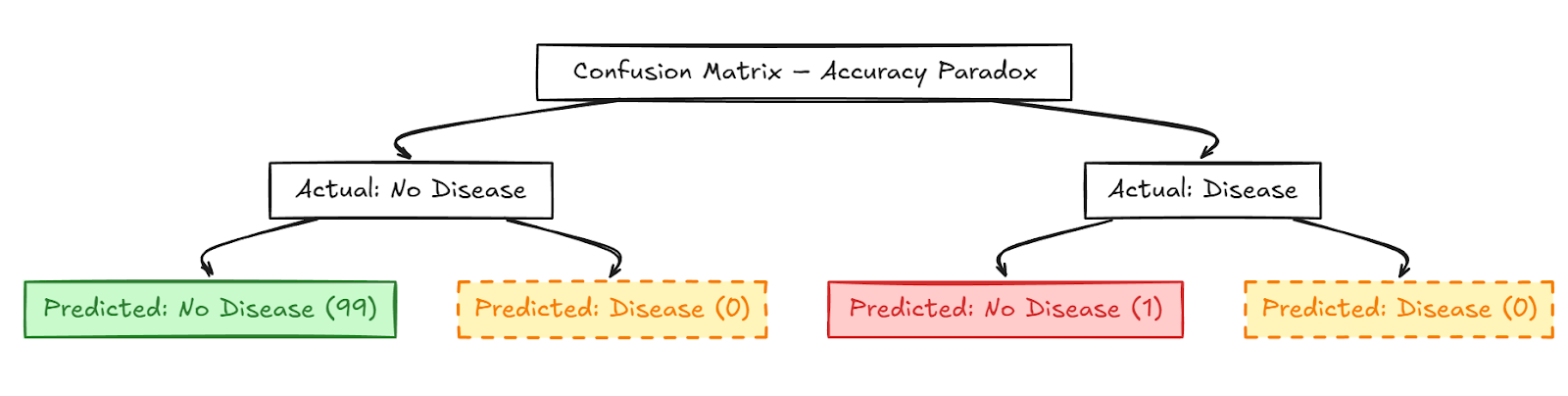
The crux of the Accuracy Paradox is that top accuracy shouldn’t be indicative of a helpful output. Let’s assume that you’re constructing a classification mannequin to determine whether or not a affected person has a uncommon illness that impacts only one in 100. The mannequin accurately identifies and labels those that do not need the illness and thereby achieves a 99% accuracy. Nevertheless, it fails to determine the one one that has the illness and wishes pressing medical consideration. Thereby, the mannequin turns into ineffective for detecting the illness, which is its very function. This happens particularly in imbalanced datasets the place the observations for one class are minimal. This has been illustrated within the determine beneath.
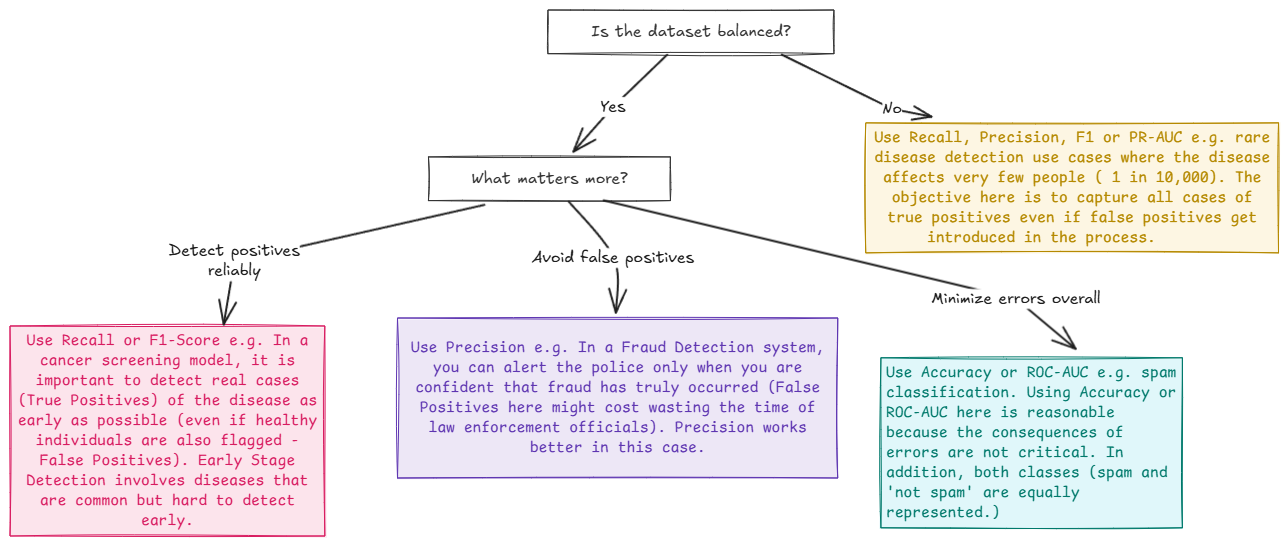
The easiest way to sort out the Accuracy paradox is to make use of metrics that seize the efficiency of the minority courses, reminiscent of Precision, Recall, and F1-score. One other method to comply with is to deal with imbalanced datasets as anomaly detection issues, as towards classification issues. One may additionally take into account gathering extra minority class knowledge (if potential), over-sampling the minority class, or undersampling the bulk class. Under is a fast information that helps decide which metric to make use of relying on the use case, goal, and penalties of errors.
Accuracy Paradox in LLMs
Whereas the Accuracy Paradox is a typical problem that many knowledge scientists sort out, its implications in LLMs are largely ignored. The Accuracy metric can dangerously overpromise in use instances that contain security, toxicity detection, and bias mitigation. A excessive accuracy doesn’t imply {that a} mannequin is honest and secure to make use of. For instance, an LLM mannequin that has a 98% accuracy is of no use if it misclassifies 2 malicious prompts as being secure and innocent. Therefore, in LLM evaluations, it’s a good suggestion to make use of recall, precision, or PR-AUC over Accuracy, as they point out how nicely the mannequin tackles minority courses.
Goodhart’s Regulation in Enterprise Intelligence
Economist Charles Goodhart acknowledged that “When a measure turns into a goal, it ceases to be an excellent measure.” This regulation is a mild reminder that when you over-optimize a metric with out understanding the implications and context, the mannequin will backfire.
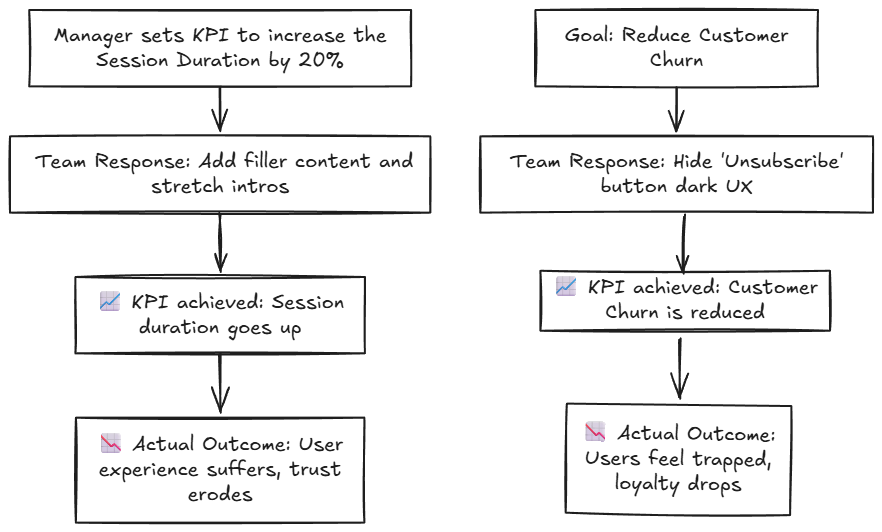
A supervisor of a fictitious on-line information company units a KPI for his group. He asks the group to work in the direction of growing the session length by 20%. The group extends introductions artificially and in addition provides filler content material to extend the session length. The session length goes up, however the video high quality is misplaced, and in consequence, the worth that customers get from the video will get diminished.
One other instance is expounded to Buyer Churn. In an try to cut back buyer churn, a subscription-based Leisure app decides to position the ‘Unsubscribe’ button in a hard-to-find location in its net portal. Consequently, the client churn reduces, however it’s not on account of improved buyer satisfaction. It’s solely due to restricted exit choices — an phantasm of buyer retention. Under is a visible illustration that demonstrates how efforts to fulfill or exceed progress targets (reminiscent of growing session length or consumer engagement) can typically result in unintended penalties, resulting in a decline in consumer expertise. When groups resort to synthetic inflation techniques to assist drive up efficiency metrics, the metric enchancment seems to be good on paper, however they don’t seem to be significant in any manner.
Goodhart’s Regulation in LLMs
Whenever you prepare an LLM an excessive amount of on a specific dataset (particularly a benchmark), it might probably begin memorizing patterns from that coaching knowledge as a substitute of studying to generalize. This can be a traditional instance of overfitting, the place the mannequin performs extraordinarily nicely on that coaching knowledge however performs poorly on real-world inputs.
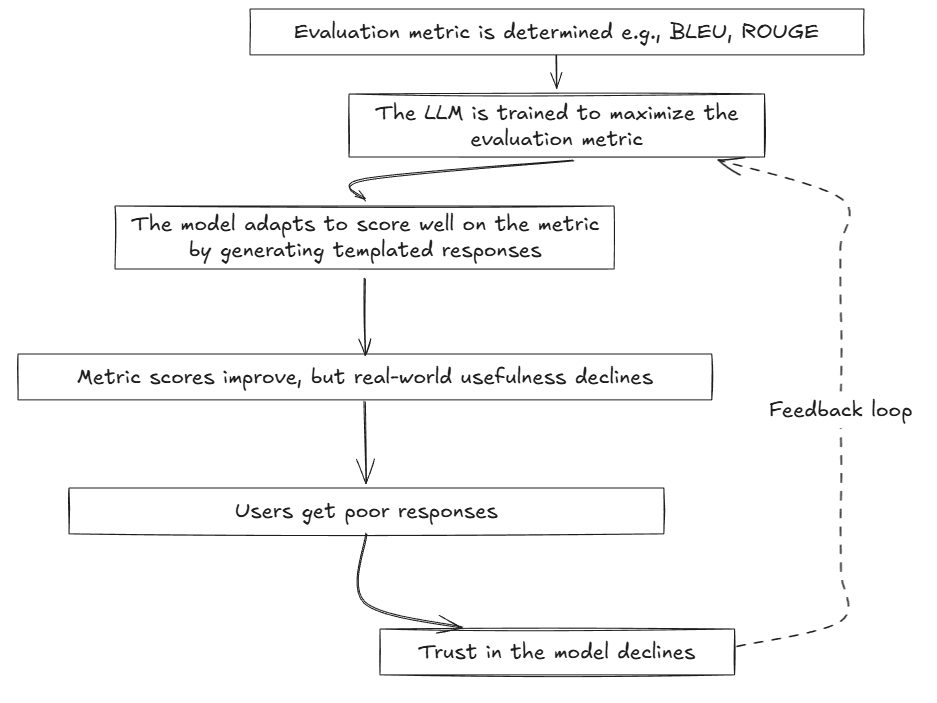
Let’s assume that you’re coaching an LLM to summarize information articles. You utilize the ROUGE (Recall-Oriented Understudy for Gisting Analysis) metric to guage the LLM’s efficiency. The ROUGE metric rewards actual or near-exact matches of n-grams with the reference summaries. Over time, the LLM begins copying massive phrases of textual content from the enter articles as a way to get an elevated ROUGE rating. It additionally makes use of buzzwords that seem rather a lot in reference summaries. Let’s assume that the enter article has the textual content “The financial institution elevated rates of interest to curb inflation, and this brought about inventory costs to say no sharply.” The overfit mannequin would summarize it as “The financial institution elevated rates of interest to curb inflation”, whereas a generalizing mannequin would summarize it as “The rate of interest hike triggered a decline within the inventory markets”. The illustration beneath demonstrates how optimizing your mannequin an excessive amount of for an analysis metric can lead to low-quality responses (responses which can be good on paper however should not useful).
Concluding Remarks
Whether or not it’s in enterprise intelligence or LLMs, paradoxes can creep in if numbers and metrics are dealt with with out the underlying nuance and context. Additionally, you will need to keep in mind that over-fitting can harm the larger image. Combining quantitative evaluation with human perception is essential to keep away from such pitfalls and create dependable stories and highly effective LLMs that really ship worth.