
Reinforcement studying (RL) is a kind of machine studying. On this strategy, algorithms be taught to make selections by trial and error, very like people do.
After we add human suggestions into the combo, this course of modifications considerably. Machines then be taught from each their actions and the steering offered by people. This mixture creates a extra dynamic studying surroundings.
On this article, we’ll speak concerning the steps of this modern strategy. We’ll begin with the fundamentals of reinforcement studying with human suggestions. Then, we’ll stroll by the important thing steps in implementing RL with human suggestions.
What’s Reinforcement Studying with Human Suggestions (RLHF)?
Reinforcement Learning from Human Feedback, or RLHF, is a technique the place AI learns from each trial and error and human enter. In customary machine studying, AI improves by numerous calculations. This course of is quick however not at all times good, particularly in duties like language.
RLHF steps in when AI, like a chatbot, wants refining. On this methodology, folks give suggestions to the AI and assist it perceive and reply higher. This methodology is particularly helpful in pure language processing (NLP). It’s utilized in chatbots, voice-to-text programs, and summarizing instruments.
Usually, AI learns by a reward system primarily based on its actions. However in advanced duties, this may be difficult. That’s the place human suggestions is crucial. It guides the AI and makes it extra logical and efficient. This strategy helps overcome the constraints of AI studying by itself.
The Purpose of RLHF
The primary intention of RLHF is to coach language fashions to provide partaking and correct textual content. This coaching entails a number of steps:
This methodology helps the AI to know when to keep away from sure questions. It learns to reject requests that contain dangerous content material like violence or discrimination.
A well known instance of a mannequin utilizing RLHF is OpenAI’s ChatGPT. This mannequin makes use of human suggestions to enhance responses and make them extra related and accountable.
Steps of Reinforcement Studying with Human Suggestions
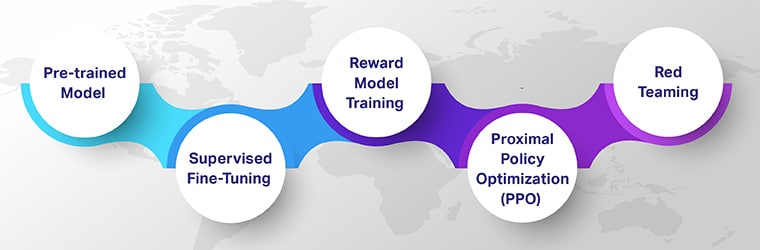
Reinforcement Studying with Human Suggestions (RLHF) ensures that AI fashions are technically proficient, ethically sound, and contextually related. Look into the 5 key steps of RLHF that discover how they contribute to creating subtle, human-guided AI programs.
-
Beginning with a Pre-trained Mannequin
The RLHF journey begins with a pre-trained mannequin, a foundational step in Human-in-the-Loop Machine Studying. Initially skilled on in depth datasets, these fashions possess a broad understanding of language or different fundamental duties however lack specialization.
Builders start with a pre-trained mannequin and get a major benefit. These fashions have already been discovered from huge quantities of knowledge. It helps them save time and sources within the preliminary coaching section. This step units the stage for extra centered and particular coaching that follows.
-
Supervised High quality-Tuning
The second step entails Supervised fine-tuning, the place the pre-trained mannequin undergoes extra coaching on a selected job or area. This step is characterised through the use of labeled information, which helps the mannequin generate extra correct and contextually related outputs.
This fine-tuning course of is a major instance of Human-guided AI Coaching, the place human judgment performs an vital position in steering the AI in direction of desired behaviors and responses. Trainers should fastidiously choose and current domain-specific information to make sure that the AI adapts to the nuances and particular necessities of the duty at hand.
-
Reward Mannequin Coaching
Within the third step, you prepare a separate mannequin to acknowledge and reward fascinating outputs that AI generates. This step is central to Suggestions-based AI Studying.
The reward mannequin evaluates the AI’s outputs. It assigns scores primarily based on standards like relevance, accuracy, and alignment with desired outcomes. These scores act as suggestions and information the AI in direction of producing higher-quality responses. This course of permits a extra nuanced understanding of advanced or subjective duties the place specific directions is likely to be inadequate for efficient coaching.
-
Reinforcement Studying by way of Proximal Coverage Optimization (PPO)
Subsequent, the AI undergoes Reinforcement Studying by way of Proximal Coverage Optimization (PPO), a classy algorithmic strategy in interactive machine studying.
PPO permits the AI to be taught from direct interplay with its surroundings. It refines its decision-making course of by rewards and penalties. This methodology is especially efficient in real-time studying and adaptation, because it helps the AI perceive the results of its actions in numerous situations.
PPO is instrumental in instructing the AI to navigate advanced, dynamic environments the place the specified outcomes may evolve or be troublesome to outline.
-
Pink Teaming
The ultimate step entails rigorous real-world testing of the AI system. Right here, a various group of evaluators, generally known as the ‘pink workforce,’ problem the AI with numerous situations. They check its skill to reply precisely and appropriately. This section ensures that the AI can deal with real-world purposes and unpredicted conditions.
Pink Teaming assessments the AI’s technical proficiency and moral and contextual soundness. They make sure that it operates inside acceptable ethical and cultural boundaries.
All through these steps, RLHF emphasizes the significance of human involvement at each stage of AI growth. From guiding the preliminary coaching with fastidiously curated information to offering nuanced suggestions and rigorous real-world testing, human enter is integral to creating AI programs which can be clever, accountable, and attuned to human values and ethics.
Conclusion
Reinforcement Studying with Human Suggestions (RLHF) reveals a brand new period in AI because it blends human insights with machine studying for extra moral, correct AI programs.
RLHF guarantees to make AI extra empathetic, inclusive, and modern. It might probably tackle biases and improve problem-solving. It’s set to rework areas like healthcare, training, and customer support.
Nevertheless, refining this strategy requires ongoing efforts to make sure effectiveness, equity, and moral alignment.