
Optical Character Recognition (OCR) has revolutionized the best way we work together with textual information in actual life, enabling machines to learn and interpret textual content from photographs, scanned paperwork, and handwritten notes. From digitizing books and automating information entry to real-time textual content translation in augmented actuality, OCR functions are extremely numerous and impactful. A few of its utility could embrace:
- Doc Digitization: Converts bodily paperwork into editable and searchable digital codecs.
- Bill Scanning: Extracts particulars like quantities, dates, and vendor names for automated processing.
- Knowledge Entry Automation: Hurries up workflows by extracting textual content from types and receipts.
- Actual-Time Translation: Interprets overseas textual content from photographs or video streams in augmented actuality.
- License Plate Recognition: Identifies automobiles in visitors techniques and parking administration.
- Accessibility Instruments: Converts textual content to speech for visually impaired people.
- Archiving and Preservation: Digitizes historic paperwork for storage and analysis.
On this put up, we take OCR a step additional by constructing a customized OCR mannequin for recognizing textual content within the Wingdings font—a symbolic font with distinctive characters usually utilized in inventive and technical contexts. Whereas conventional OCR fashions are skilled for traditional textual content, this practice mannequin bridges the hole for area of interest functions, unlocking potentialities for translating symbolic textual content into readable English, whether or not for accessibility, design, or archival functions. By this, we show the ability of OCR to adapt and cater to specialised use instances within the trendy world.
Is There a Want for Customized OCR within the Age of Imaginative and prescient-Language Fashions?
Imaginative and prescient-language fashions, comparable to Flamingo, Qwen2-VL, have revolutionized how machines perceive photographs and textual content by bridging the hole between the 2 modalities. They’ll course of and cause about photographs and related textual content in a extra generalized method.
Regardless of their spectacular capabilities, there stays a necessity for customized OCR techniques in particular situations, primarily attributable to:
- Accuracy for Particular Languages or Scripts: Many vision-language fashions concentrate on widely-used languages. Customized OCR can handle low-resource or regional languages, together with Indic scripts, calligraphy, or underrepresented dialects.
- Light-weight and Useful resource-Constrained Environments: Customized OCR fashions might be optimized for edge gadgets with restricted computational energy, comparable to embedded techniques or cell functions. Imaginative and prescient-language fashions, in distinction, are sometimes too resource-intensive for such use instances. For real-time or high-volume functions, comparable to bill processing or automated doc evaluation, customized OCR options might be tailor-made for pace and accuracy.
- Knowledge Privateness and Safety: Sure industries, comparable to healthcare or finance, require OCR options that function offline or inside non-public infrastructures to satisfy strict information privateness rules. Customized OCR ensures compliance, whereas cloud-based vision-language fashions may introduce safety issues.
- Value-Effectiveness: Deploying and fine-tuning large vision-language fashions might be cost-prohibitive for small-scale companies or particular tasks. Customized OCR generally is a extra inexpensive and centered different.
Construct a Customized OCR Mannequin for Wingdings
To discover the potential of customized OCR techniques, we’ll construct an OCR engine particularly for the Wingdings font.
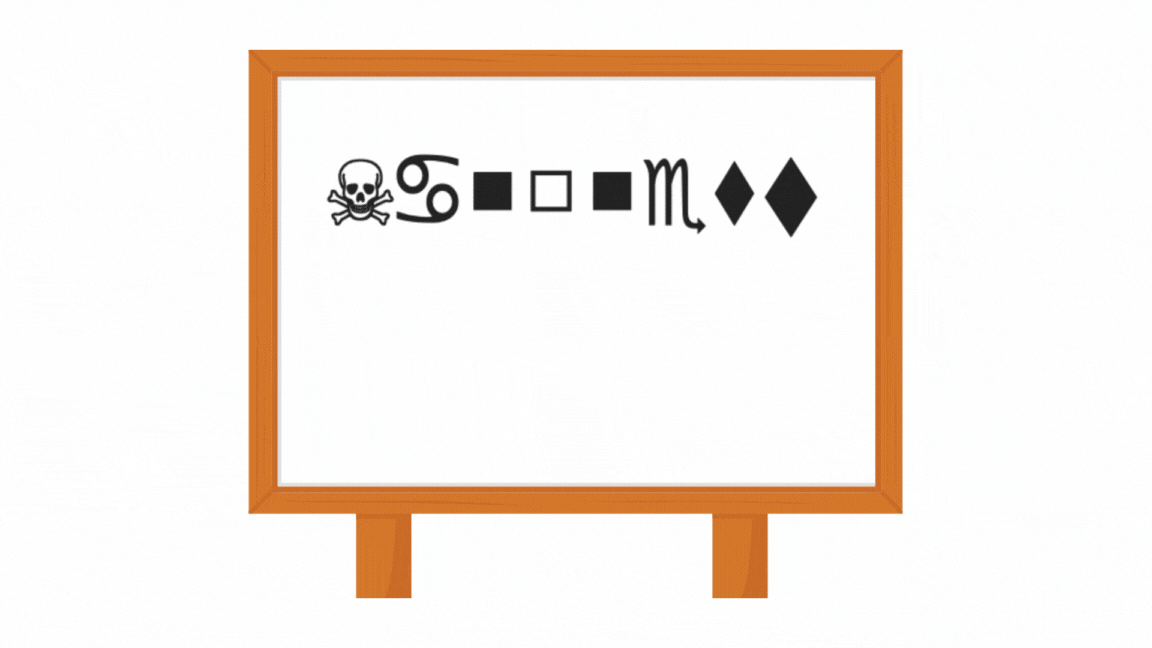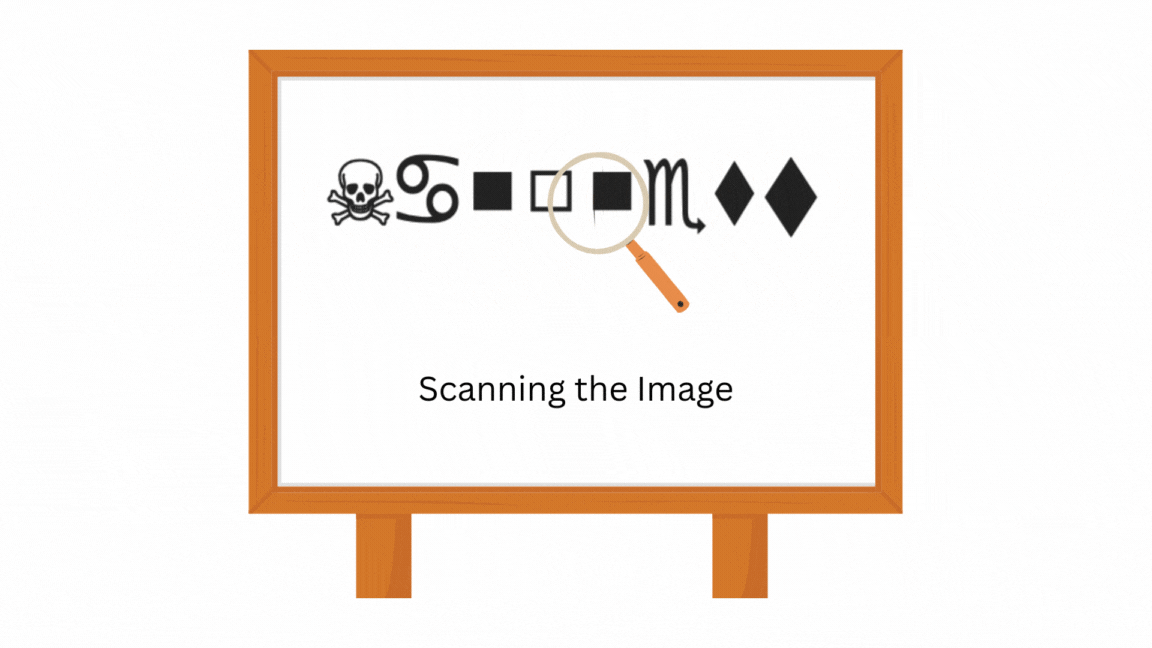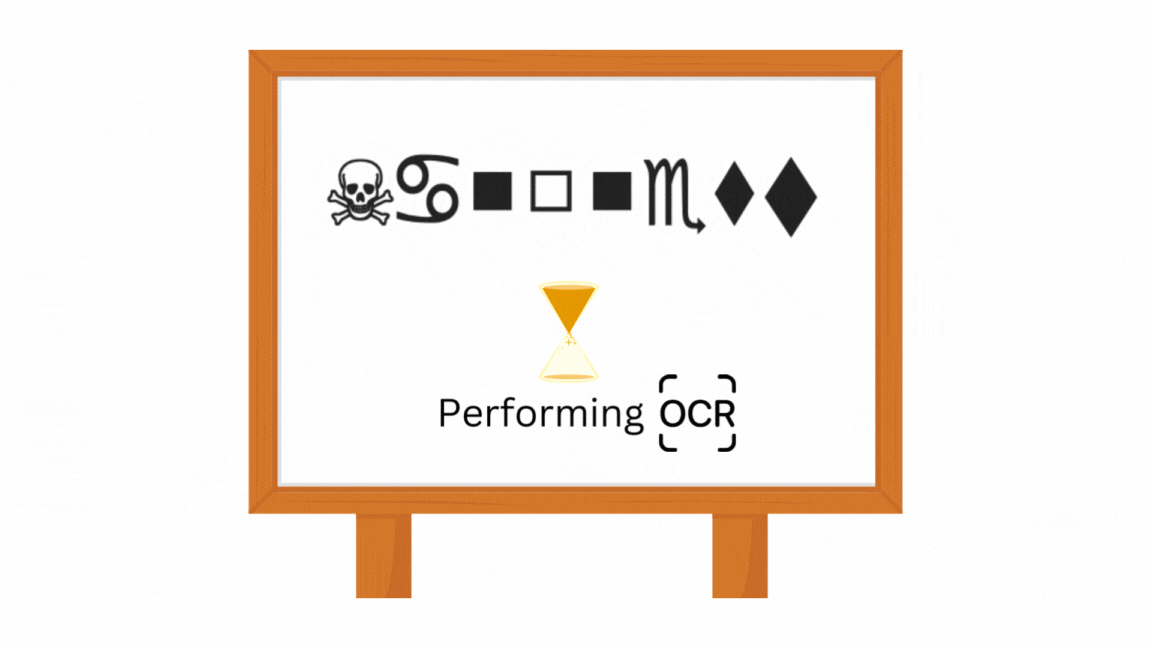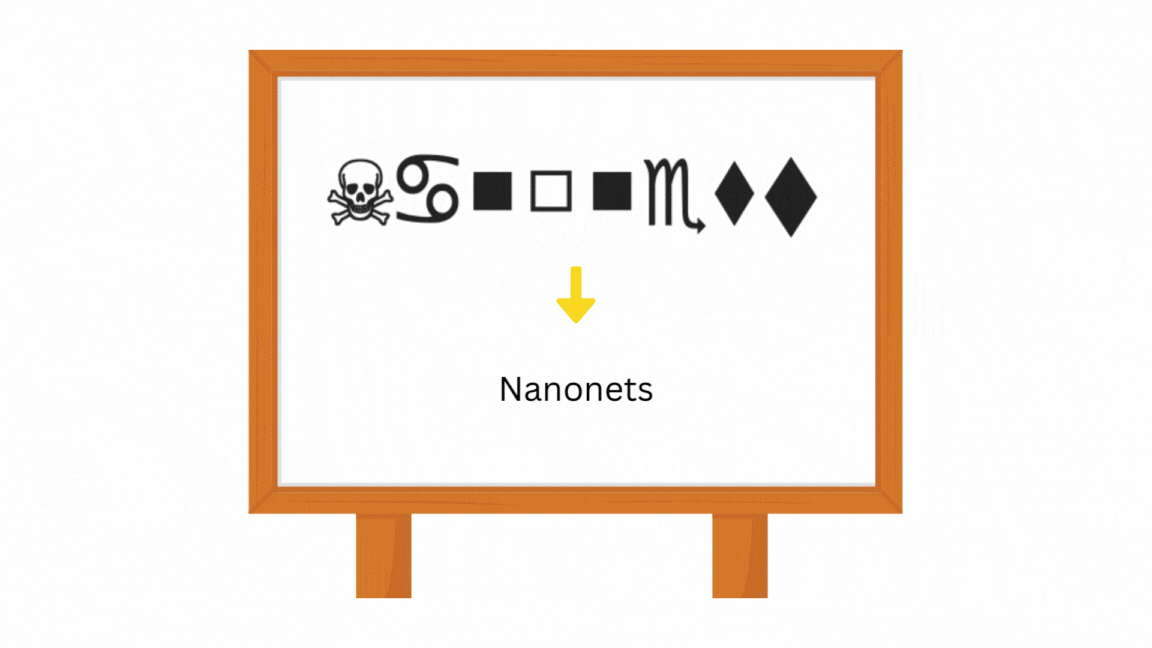
Beneath are the steps and elements we’ll comply with:
- Generate a customized dataset of Wingdings font photographs paired with their corresponding labels in English phrases.
- Create a customized OCR mannequin able to recognizing symbols within the Wingdings font. We are going to use the Imaginative and prescient Transformer for Scene Textual content Recognition (ViTSTR), a state-of-the-art structure designed for image-captioning duties. In contrast to conventional CNN-based fashions, ViTSTR leverages the transformer structure, which excels at capturing long-range dependencies in photographs, making it superb for recognizing complicated textual content constructions, together with the intricate patterns of Wingdings fonts.
- Prepare the mannequin on the customized dataset of Wingdings symbols.
- Check the mannequin on unseen information to guage its accuracy.
For this undertaking, we’ll make the most of Google Colab for coaching, leveraging its 16 GB T4 GPU for sooner computation.
Making a Wingdings Dataset
What’s Wingdings?
Wingdings is a symbolic font developed by Microsoft that consists of a set of icons, shapes, and pictograms as an alternative of conventional alphanumeric characters. Launched in 1990, Wingdings maps keyboard inputs to graphical symbols, comparable to arrows, smiley faces, checkmarks, and different ornamental icons. It’s usually used for design functions, visible communication, or as a playful font in digital content material.
Because of its symbolic nature, decoding Wingdings textual content programmatically poses a problem, making it an attention-grabbing use case for customized OCR techniques.
Dataset Creation
Since no present dataset is on the market for Optical Character Recognition (OCR) in Wingdings font, we created one from scratch. The method entails producing photographs of phrases within the Wingdings font and mapping them to their corresponding English phrases.
To realize this, we used the Wingdings Translator to transform English phrases into their Wingdings representations. For every transformed phrase, a picture was manually generated and saved in a folder named “wingdings_word_images”.
Moreover, we create a “metadata.csv” file to keep up a structured report of the dataset together with the picture path. This file comprises two columns:
- Picture Path: Specifies the file path for every picture within the dataset.
- English Phrase: Lists the corresponding English phrase for every Wingdings illustration.
The dataset might be downloaded from this link.
Preprocessing the Dataset
The photographs within the dataset differ in dimension because of the guide creation course of. To make sure uniformity and compatibility with OCR fashions, we preprocess the photographs by resizing and padding them.
import pandas as pd
import numpy as np
from PIL import Picture
import os
from tqdm import tqdm
def pad_image(picture, target_size=(224, 224)):
"""Pad picture to focus on dimension whereas sustaining side ratio"""
if picture.mode != 'RGB':
picture = picture.convert('RGB')
# Get present dimension
width, top = picture.dimension
# Calculate padding
aspect_ratio = width / top
if aspect_ratio > 1:
# Width is bigger
new_width = target_size[0]
new_height = int(new_width / aspect_ratio)
else:
# Top is bigger
new_height = target_size[1]
new_width = int(new_height * aspect_ratio)
# Resize picture sustaining side ratio
picture = picture.resize((new_width, new_height), Picture.Resampling.LANCZOS)
# Create new picture with padding
new_image = Picture.new('RGB', target_size, (255, 255, 255))
# Paste resized picture in middle
paste_x = (target_size[0] - new_width) // 2
paste_y = (target_size[1] - new_height) // 2
new_image.paste(picture, (paste_x, paste_y))
return new_image
# Learn the metadata
df = pd.read_csv('metadata.csv')
# Create output listing for processed photographs
processed_dir="processed_images"
os.makedirs(processed_dir, exist_ok=True)
# Course of every picture
new_paths = []
for idx, row in tqdm(df.iterrows(), whole=len(df), desc="Processing photographs"):
# Load picture
img_path = row['image_path']
img = Picture.open(img_path)
# Pad picture
processed_img = pad_image(img)
# Save processed picture
new_path = os.path.be a part of(processed_dir, f'processed_{os.path.basename(img_path)}')
processed_img.save(new_path)
new_paths.append(new_path)
# Replace dataframe with new paths
df['processed_image_path'] = new_paths
df.to_csv('processed_metadata.csv', index=False)
print("Picture preprocessing accomplished!")
print(f"Complete photographs processed: {len(df)}")
First, every picture is resized to a hard and fast top whereas sustaining its side ratio to protect the visible construction of the Wingdings characters. Subsequent, we apply padding to make all photographs the identical dimensions, sometimes a sq. form, to suit the enter necessities of neural networks. The padding is added symmetrically across the resized picture, with the background coloration matching the unique picture’s background.
Splitting the Dataset
The dataset is split into three subsets: coaching (70%), validation (dev) (15%), and testing (15%). The coaching set is used to show the mannequin, the validation set helps fine-tune hyperparameters and monitor overfitting, and the take a look at set evaluates the mannequin’s efficiency on unseen information. This random break up ensures every subset is numerous and consultant, selling efficient generalization.
import pandas as pd
from sklearn.model_selection import train_test_split
# Learn the processed metadata
df = pd.read_csv('processed_metadata.csv')
# First break up: prepare and momentary
train_df, temp_df = train_test_split(df, train_size=0.7, random_state=42)
# Second break up: validation and take a look at from momentary
val_df, test_df = train_test_split(temp_df, train_size=0.5, random_state=42)
# Save splits to CSV
train_df.to_csv('prepare.csv', index=False)
val_df.to_csv('val.csv', index=False)
test_df.to_csv('take a look at.csv', index=False)
print("Knowledge break up statistics:")
print(f"Coaching samples: {len(train_df)}")
print(f"Validation samples: {len(val_df)}")
print(f"Check samples: {len(test_df)}")
Visualizing the Dataset
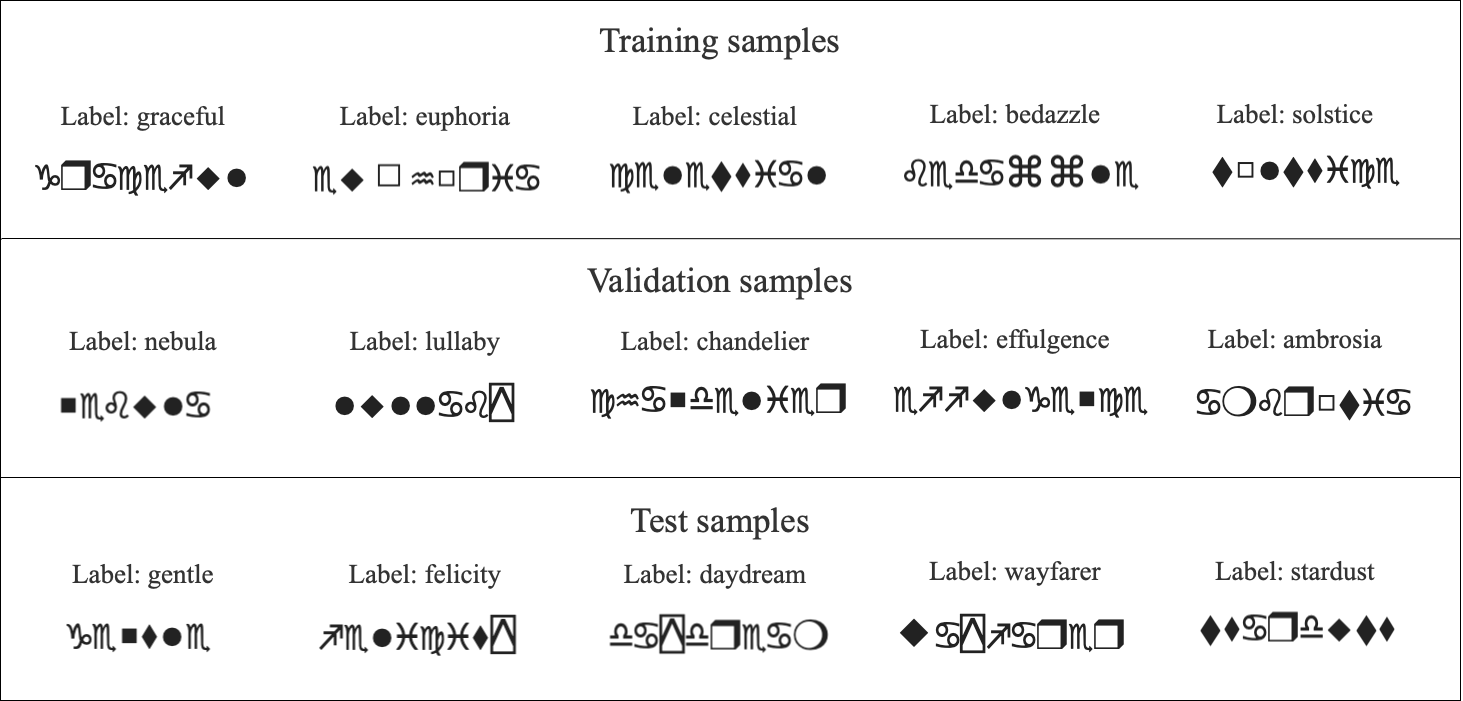
To higher perceive the dataset, we visualize samples from every break up. Particularly, we show 5 examples from the coaching set, 5 from the validation set, and 5 from the take a look at set. Every visualization contains the Wingdings textual content as a picture alongside its corresponding label in English. This step offers a transparent overview of the info distribution throughout the splits and ensures the correctness of the dataset mappings.
import matplotlib.pyplot as plt
from PIL import Picture
import pandas as pd
def plot_samples(df, num_samples=5, title="Pattern Photographs"):
# Set bigger font sizes
plt.rcParams.replace({
'font.dimension': 14, # Base font dimension
'axes.titlesize': 16, # Subplot title font dimension
'determine.titlesize': 20 # Predominant title font dimension
})
fig, axes = plt.subplots(1, num_samples, figsize=(20, 4))
fig.suptitle(title, fontsize=20, y=1.05)
# Randomly pattern photographs
sample_df = df.pattern(n=num_samples)
for idx, (_, row) in enumerate(sample_df.iterrows()):
img = Picture.open(row['processed_image_path'])
axes[idx].imshow(img)
axes[idx].set_title(f"Label: {row['english_word_label']}", fontsize=16, pad=10)
axes[idx].axis('off')
plt.tight_layout()
plt.present()
# Load splits
train_df = pd.read_csv('prepare.csv')
val_df = pd.read_csv('val.csv')
test_df = pd.read_csv('take a look at.csv')
# Plot samples from every break up
plot_samples(train_df, title="Coaching Samples")
plot_samples(val_df, title="Validation Samples")
plot_samples(test_df, title="Check Samples")
Samples from the info are visualised as:
Prepare an OCR Mannequin
First we have to import the required libraries and dependencies:
import torch
import torch.nn as nn
from torch.utils.information import Dataset, DataLoader
from transformers import VisionEncoderDecoderModel, ViTImageProcessor, AutoTokenizer
from PIL import Picture
import pandas as pd
from tqdm import tqdm
Mannequin Coaching with ViTSTR
We use a Imaginative and prescient Encoder-Decoder mannequin, particularly ViTSTR (Imaginative and prescient Transformer for Scene Textual content Recognition). We fine-tune it for our Wingdings OCR activity. The encoder processes the Wingdings textual content photographs utilizing a ViT (Imaginative and prescient Transformer) spine, whereas the decoder generates the corresponding English phrase labels.
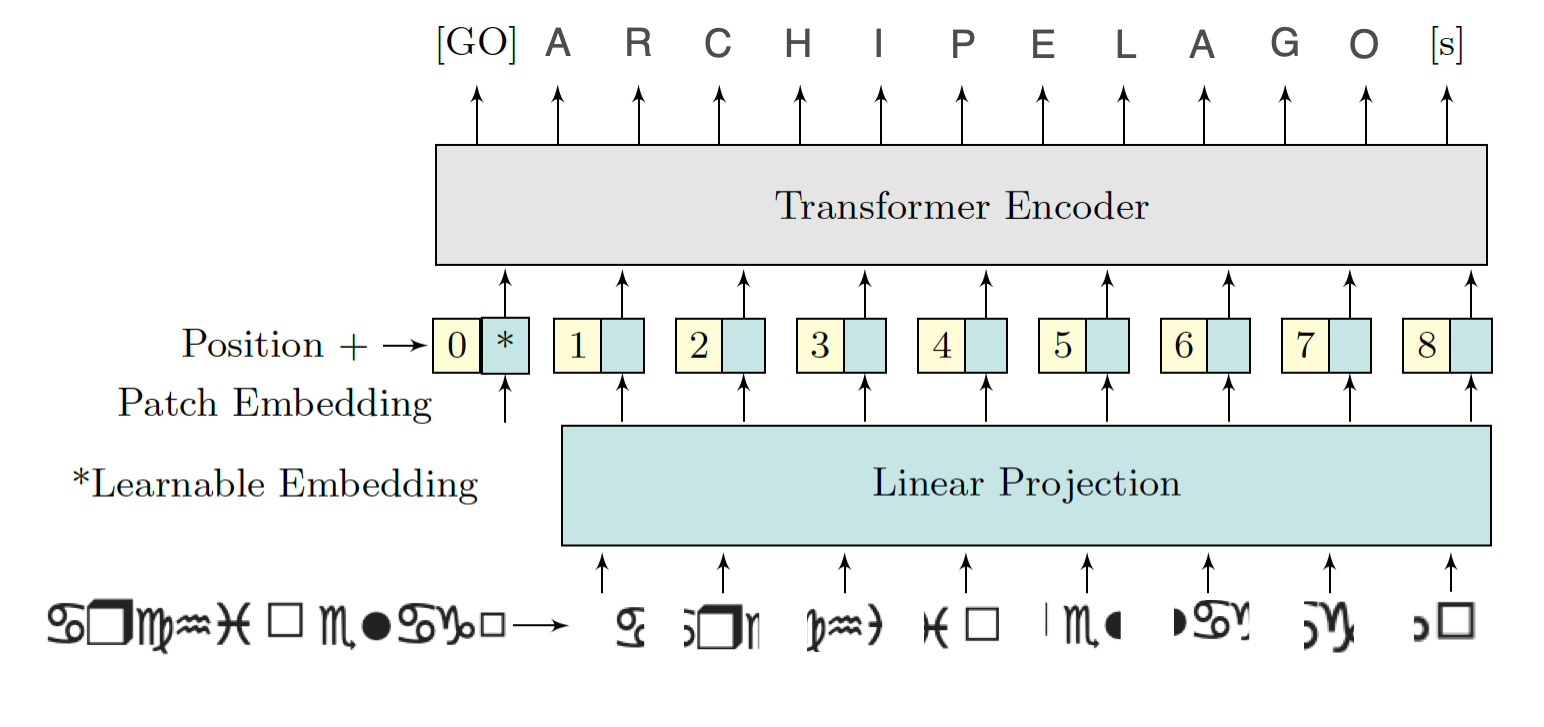
Throughout coaching, the mannequin learns to map pixel-level data from the photographs to significant English textual content. The coaching and validation losses are monitored to evaluate mannequin efficiency, guaranteeing it generalizes nicely. After coaching, the fine-tuned mannequin is saved for inference on unseen Wingdings textual content photographs. We use pre-trained elements from Hugging Face for our OCR pipeline and wonderful tune them. The ViTImageProcessor prepares photographs for the Imaginative and prescient Transformer (ViT) encoder, whereas the bert-base-uncased tokenizer processes English textual content labels for the decoder. The VisionEncoderDecoderModel, combining a ViT encoder and GPT-2 decoder, is fine-tuned for picture captioning duties, making it superb for studying the Wingdings-to-English mapping.
class WingdingsDataset(Dataset):
def __init__(self, csv_path, processor, tokenizer):
self.df = pd.read_csv(csv_path)
self.processor = processor
self.tokenizer = tokenizer
def __len__(self):
return len(self.df)
def __getitem__(self, idx):
row = self.df.iloc[idx]
picture = Picture.open(row['processed_image_path'])
label = row['english_word_label']
# Course of picture
pixel_values = self.processor(picture, return_tensors="pt").pixel_values
# Course of label
encoding = self.tokenizer(
label,
padding="max_length",
max_length=16,
truncation=True,
return_tensors="pt"
)
return {
'pixel_values': pixel_values.squeeze(),
'labels': encoding.input_ids.squeeze(),
'textual content': label
}
def train_epoch(mannequin, dataloader, optimizer, machine):
mannequin.prepare()
total_loss = 0
progress_bar = tqdm(dataloader, desc="Coaching")
for batch in progress_bar:
pixel_values = batch['pixel_values'].to(machine)
labels = batch['labels'].to(machine)
outputs = mannequin(pixel_values=pixel_values, labels=labels)
loss = outputs.loss
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.merchandise()
progress_bar.set_postfix({'loss': loss.merchandise()})
return total_loss / len(dataloader)
def validate(mannequin, dataloader, machine):
mannequin.eval()
total_loss = 0
with torch.no_grad():
for batch in tqdm(dataloader, desc="Validating"):
pixel_values = batch['pixel_values'].to(machine)
labels = batch['labels'].to(machine)
outputs = mannequin(pixel_values=pixel_values, labels=labels)
loss = outputs.loss
total_loss += loss.merchandise()
return total_loss / len(dataloader)
# Initialize fashions and tokenizers
processor = ViTImageProcessor.from_pretrained("google/vit-base-patch16-224-in21k")
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
mannequin = VisionEncoderDecoderModel.from_pretrained("nlpconnect/vit-gpt2-image-captioning")
# Create datasets
train_dataset = WingdingsDataset('prepare.csv', processor, tokenizer)
val_dataset = WingdingsDataset('val.csv', processor, tokenizer)
# Create dataloaders
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=32)
# Setup coaching
machine = torch.machine('cuda' if torch.cuda.is_available() else 'cpu')
mannequin = mannequin.to(machine)
optimizer = torch.optim.AdamW(mannequin.parameters(), lr=5e-5)
num_epochs = 20 #(change in line with want)
# Coaching loop
for epoch in vary(num_epochs):
print(f"nEpoch {epoch+1}/{num_epochs}")
train_loss = train_epoch(mannequin, train_loader, optimizer, machine)
val_loss = validate(mannequin, val_loader, machine)
print(f"Coaching Loss: {train_loss:.4f}")
print(f"Validation Loss: {val_loss:.4f}")
# Save the mannequin
mannequin.save_pretrained('wingdings_ocr_model')
print("nTraining accomplished and mannequin saved!")
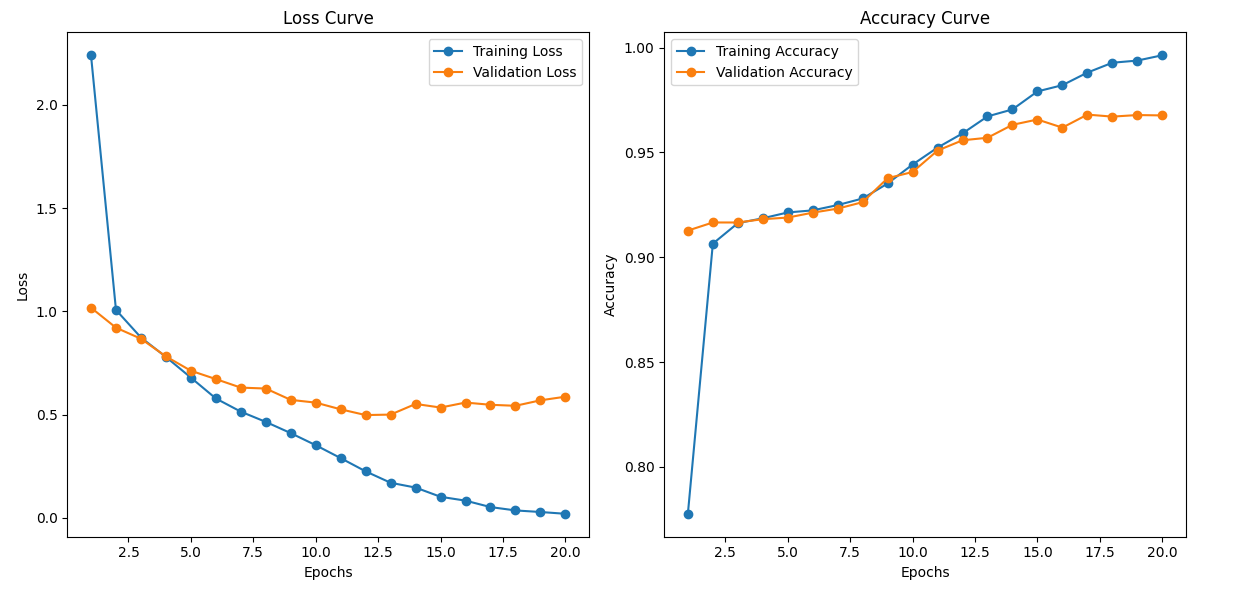
The coaching is carried for 20 epochs in Google Colab. Though it offers truthful end result with 20 epochs, it is a hyper parameter and might be elevated to achieve higher accuracy. Dropout, Picture Augmentation and Batch Normalization are just a few extra hyper-parameters one can play with to make sure mannequin just isn’t overfitting. The coaching stats and the loss and accuracy curve for prepare and validation units on first and final epochs are given under:
Epoch 1/20
Coaching: 100%|██████████| 22/22 [00:36<00:00, 1.64s/it, loss=1.13]
Validating: 100%|██████████| 5/5 [00:02<00:00, 1.71it/s]
Coaching Loss: 2.2776
Validation Loss: 1.0183
..........
..........
..........
..........
Epoch 20/20
Coaching: 100%|██████████| 22/22 [00:35<00:00, 1.61s/it, loss=0.0316]
Validating: 100%|██████████| 5/5 [00:02<00:00, 1.73it/s]
Coaching Loss: 0.0246
Validation Loss: 0.5970
Coaching accomplished and mannequin saved!
Utilizing the Saved Mannequin
As soon as the mannequin has been skilled and saved, you possibly can simply load it for inference on new Wingdings photographs. The take a look at.csv file created throughout preprocessing is used to create the test_dataset. Right here’s the code to load the saved mannequin and make predictions:
# Load the skilled mannequin
mannequin = VisionEncoderDecoderModel.from_pretrained('wingdings_ocr_model')
processor = ViTImageProcessor.from_pretrained("google/vit-base-patch16-224-in21k")
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
# Create take a look at dataset and dataloader
test_dataset = WingdingsDataset('take a look at.csv', processor, tokenizer)
test_loader = DataLoader(test_dataset, batch_size=32)
Mannequin Analysis
After coaching, we consider the mannequin’s efficiency on the take a look at break up to measure its efficiency. To realize insights into the mannequin’s efficiency, we randomly choose 10 samples from the take a look at break up. For every pattern, we show the true label (English phrase) alongside the mannequin’s prediction and test in the event that they match.
import seaborn as sns
import matplotlib.pyplot as plt
from PIL import Picture
def plot_prediction_samples(image_paths, true_labels, pred_labels, num_samples=10):
# Set determine dimension and font sizes
plt.rcParams.replace({
'font.dimension': 14,
'axes.titlesize': 18,
'determine.titlesize': 22
})
# Calculate grid dimensions
num_rows = 2
num_cols = 5
num_samples = min(num_samples, len(image_paths))
# Create determine
fig, axes = plt.subplots(num_rows, num_cols, figsize=(20, 8))
fig.suptitle('Pattern Predictions from Check Set', fontsize=22, y=1.05)
# Flatten axes for simpler indexing
axes_flat = axes.flatten()
for i in vary(num_samples):
ax = axes_flat[i]
# Load and show picture
img = Picture.open(image_paths[i])
ax.imshow(img)
# Create label textual content
true_text = f"True: {true_labels[i]}"
pred_text = f"Pred: {pred_labels[i]}"
# Set coloration based mostly on correctness
coloration="inexperienced" if true_labels[i] == pred_labels[i] else 'pink'
# Add textual content above picture
ax.set_title(f"{true_text}n{pred_text}",
fontsize=14,
coloration=coloration,
pad=10,
bbox=dict(facecolor="white",
alpha=0.8,
edgecolor="none",
pad=3))
# Take away axes
ax.axis('off')
# Take away any empty subplots
for i in vary(num_samples, num_rows * num_cols):
fig.delaxes(axes_flat[i])
plt.tight_layout()
plt.present()
# Analysis
machine = torch.machine('cuda' if torch.cuda.is_available() else 'cpu')
mannequin = mannequin.to(machine)
mannequin.eval()
predictions = []
ground_truth = []
image_paths = []
with torch.no_grad():
for batch in tqdm(test_loader, desc="Evaluating"):
pixel_values = batch['pixel_values'].to(machine)
texts = batch['text']
outputs = mannequin.generate(pixel_values)
pred_texts = tokenizer.batch_decode(outputs, skip_special_tokens=True)
predictions.prolong(pred_texts)
ground_truth.prolong(texts)
image_paths.prolong([row['processed_image_path'] for _, row in test_dataset.df.iterrows()])
# Calculate and print accuracy
accuracy = accuracy_score(ground_truth, predictions)
print(f"nTest Accuracy: {accuracy:.4f}")
# Show pattern predictions in grid
print("nDisplaying pattern predictions:")
plot_prediction_samples(image_paths, ground_truth, predictions)
The analysis offers the next output:

Analysing the output given by the mannequin, we discover that the predictions match the reference/unique labels pretty nicely. Though the final prediction is right it’s displayed in pink due to the areas within the generated textual content.
All of the code and dataset used above might be discovered on this Github repository. And the top to finish coaching might be discovered within the following colab pocket book
Dialogue
After we see the outputs, it turns into clear that the mannequin performs very well. The anticipated labels are correct, and the visible comparability with the true labels demonstrates the mannequin’s sturdy functionality in recognizing the right courses.
The mannequin’s glorious efficiency might be attributed to the strong structure of the Imaginative and prescient Transformer for Scene Textual content Recognition (ViTSTR). ViTSTR stands out attributable to its potential to seamlessly mix the ability of Imaginative and prescient Transformers (ViT) with language fashions for textual content recognition duties.
A comparability might be made by experimenting with completely different ViT structure sizes, comparable to various the variety of layers, embedding dimensions, or the variety of consideration heads. Fashions like ViT-Base, ViT-Giant, and ViT-Big might be examined, together with different architectures like:
- DeiT (Knowledge-efficient Picture Transformer)
- Swin Transformer
By evaluating these fashions of various scales, we will determine which structure is essentially the most environment friendly by way of efficiency and computational sources. This may assist decide the optimum mannequin dimension that balances accuracy and effectivity for the given activity.
For duties like extracting data from paperwork, instruments comparable to Nanonets’ Chat with PDF have evaluated and used a number of state of the LLMs together with customized in-house skilled fashions and might supply a dependable strategy to work together with content material, guaranteeing correct information extraction with out danger of misrepresentation.