
Giant Language Fashions (LLMs) corresponding to GPT-4 and Llama 3 have affected the AI panorama and carried out wonders starting from customer support to content material era. Nevertheless, adapting these fashions for particular wants normally means selecting between two highly effective methods: Retrieval-Augmented Era (RAG) and fine-tuning.
Whereas each these approaches improve LLMs, they’re articulate in direction of totally different goals and are profitable in numerous conditions. Allow us to research these two strategies intimately benefits and drawbacks and the way one could choose one for his or her want.
Retrieval-Augmented Era (RAG)- What’s It?
RAG is an strategy that synergizes the generative capabilities of LLMs with retrieval for contextually exact solutions. Quite than solely utilizing the information it examined on, RAG fetches related data by way of exterior databases or information repositories to infuse the data within the answer-generating course of.
How RAG Works
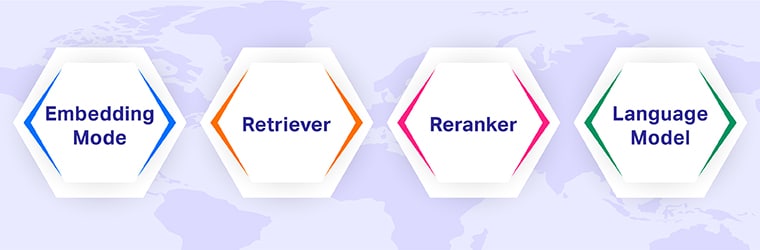
- Embedding Mannequin: Embeds each the paperwork and the queries into the vector house to make a comparability extra environment friendly.
- Retriever: Appears to be like right into a information base by way of embeddings to seize related paperwork.
- Reranker: Scores the retrieved paperwork based on how related they’re.
- Language mannequin: Merges retrieved information with a consumer’s queries into one response.
Benefits of RAG
- Dynamic Data Upgrades: Offers an environment friendly hit of data with the replace processes significantly decreased by means of the method of mannequin retraining.
- Discount of Hallucination: By correctly grounding responses on exterior information, RAG minimizes factual inaccuracies.
- Scalability: Could be simply imbedded into giant, numerous datasets thereby permitting its choices for helpful open-ended and dynamic duties, corresponding to buyer brokers and information summarization.
Limitations of RAG
- Latency: The very attentiveness in data extraction, delays the output time which leads to greater latency and makes it irrelevant for real-time work environments.
- High quality of Data Base: Dependability within the retrieval and relevance of exterior information turns into vital as solutions rely solely on these sources.

Fantastic-Tuning- What Is It?

Fantastic-tuning is a strategy of retraining a pre-trained LLM on a particular area dataset within the preparation of specialised job execution, permitting the mannequin to completely perceive nuanced patterns current inside the restrict of a sure context.
How Fantastic-Tuning Works

- Knowledge Preparation: Job-specific datasets should be cleaned and put aside into coaching, validation, and testing subsets.
- Mannequin Coaching: The LLM should prepare on this dataset with strategies that embody backpropagation and gradient descent.
- Contents of Hyperparameter Tuning: Offers fine-tuning on a number of of the vital hyperparameter contents corresponding to batch dimension, and studying charge, amongst others.
Benefits of Fantastic-Tuning
- Customization: Permits authorities over the mannequin’s actions, tone, and magnificence in outputs.
- Effectivity in Inference: When an LLM has been fine-tuned, it produces fast responses with none exterior retrieval course of.
- Specialised Skillset: Greatest suited to purposes that require high quality and accuracy throughout well-understood domains, corresponding to freezing, medical evaluations, and contract evaluation.
Cons of Fantastic-Tuning
- Useful resource-Intensive: Requires each nice computing energy and adequately high-quality labeled information.
- Catastrophic Forgetting: Fantastic-tuning tends to overwrite beforehand acquired generic information and thereby restrict its potential to cater to new duties.
- Static Data Base: As soon as coaching has been accomplished, its information stays intact until retaught on further new information.
Key Variations Between RAG and Fantastic-Tuning
| Function | Retrieval-Augmented Era (RAG) |
Fantastic-Tuning |
|---|---|---|
| Data Supply |
Exterior databases (dynamic) | Internalized throughout coaching (static) |
| Adaptability to New Knowledge | Excessive; updates by way of exterior sources | Low; requires retraining |
| Latency | Larger on account of retrieval steps | Low; direct response era |
| Customization | Restricted; depends on exterior information | Excessive; tailor-made to particular duties |
| Scalability | Simply scales with giant datasets | Useful resource-intensive at scale |
| Use Case Examples | Actual-time Q&A, fact-checking | Sentiment evaluation, domain-specific duties |
When to Select RAG vs. Fantastic-Tuning
Software space needing real-time data
If the appliance wants real-time, up-to-date information, then RAG have to be used: information summarization and buyer help programs counting on the quickly altering information. Instance: Digital assistant fetching stay updates like inventory costs and climate information.
Area Experience
When fine-tuning is required for the precision of a slim area, one can both go for fine-tuning within the areas of authorized doc evaluate and medical textual content evaluation. Instance: A fine-tuned mannequin educated on medical literature to be used within the analysis of situations based mostly on affected person notes.
Scale
RAG is on-prominent with scaling for open-ended queries in our house, fetching the findings from totally different information bases dynamically. Instance: A search engine with real-case solutions offering multi-industry feedback with out retraining.
Useful resource availability
Fantastic-tuning may be a greater total choice for smaller-scale use circumstances the place a static dataset would suffice. Instance: A bot educated on a set of FAQs used internally by an organization.
Rising Developments
- Hybrid Approaches: Combining RAG with minimizing, one of the best of each worlds. For instance:
- RAG for retrieving dynamic context whereas fine-tuning the language mannequin on task-specific nuances. Instance: authorized assistants accessing case legal guidelines whereas summarizing them coherently.
- Parameter-efficient fine-tuning (PEFT): LoRA (low-rank adaptation) assists within the effort of minimizing parameter updates throughout fine-tuning, thus resulting in very restricted computing efforts whereas offering most accuracies.
- Multimodal RAG: Future advances will undertake a blended view into RAG programs by combining textual content, photographs, and audio for wealthy interplay over totally different media.
- Reinforcement Studying in RAG: Reinforcement studying can assist optimize retrieval methods by rewarding the fashions to generate extra related and significant outputs.
[Also Read: Revolutionizing AI with Multimodal Large Language Models (MLLMs)]
Actual-world examples of
| RAG | Fantastic-tuning |
|---|---|
| Digital assistants corresponding to Siri and Alexa retrieve stay data. | Sentiment evaluation fashions are finally meant for monitoring social media. |
| Buyer help instruments that categorize tickets utilizing historic information and FAQs. | Authorized AI educated on jurisdiction-based case legislation. |
| Analysis instruments retrieve papers from educational journals in actual time to ship sure insights. | Translation fashions that may be fine-tuned for industry-specifying language pairs. |
Conclusion
Each RAG and fine-tuning are highly effective methods outlined to resolve totally different challenges in optimizing LLMs. Go for RAG when attentiveness in direction of analysis, scaling, and retrieval in real-time is major, and, in distinction, fine-tuning when task-oriented precision, customization, and experience are musts.