
, I mentioned how to create your first DataFrame utilizing Pandas. I discussed that the very first thing that you must grasp is Information buildings and arrays earlier than transferring on to knowledge evaluation with Python.
Pandas is a wonderful library for knowledge manipulation and retrieval. Mix it with Numpy and Seaborne, and also you’ve bought your self a powerhouse for knowledge evaluation.
On this article, I’ll be strolling you thru sensible methods to filter knowledge in pandas, beginning with easy circumstances and transferring on to highly effective strategies like .isin(), .str.startswith(), and .question(). By the top, you’ll have a toolkit of filtering methods you may apply to any dataset.
With out additional ado, let’s get into it!
Importing our knowledge
Okay, to start out, I’ll import our pandas library
# importing the pandas library
import pandas as pdThat’s the one library I’ll want for this use case
Subsequent, I’ll import the dataset. The dataset comes from ChatGPT, btw. It consists of primary gross sales transaction data. Let’s check out our dataset.
# trying out our knowledge
df_sales = pd.read_csv('sales_data.csv')
df_salesRight here’s a preview of the information
It consists of primary gross sales data with columns OrderId, Buyer, Product, Class, Amount, Worth, OrderDate and Area.
Alright, let’s start our filtering!
Filtering by a single situation
Let’s attempt to choose all data from a specific class. As an example, I need to know what number of distinctive orders have been made within the Electronics class. To do this, it’s fairly simple
# Filter by a single situation
# Instance: All orders from the “Electronics” class.
df_sales[‘Category’] == ‘Electronics’In Python, that you must distinguish between the = operator and the == operator.
= is used to assign a worth to a variable.
As an example
x = 10 # Assigns the worth 10 to the variable x== then again is used to match two values collectively. As an example
a = 3
b = 3
print(a == b) # Output: True
c = 5
d = 10
print(c == d) # Output: FalseWith that stated, let’s apply the identical notion to the filtering I did above
# Filter by a single situation
# Instance: All orders from the “Electronics” class.
df_sales[‘Category’] == ‘Electronics’Right here, I’m principally telling Python to go looking by our whole file to discover a class named Electronics. When it finds a match, it shows a Boolean consequence, True or False. Right here’s the consequence

As you may see. We’re getting a Boolean output. True means Electronics exists, whereas False means the latter. That is okay and all, however it will probably turn into complicated if you happen to’re coping with a lot of data. Let’s repair that.
# Filter by a single situation
# Instance: All orders from the “Electronics” class.
df_sales[df_sales[‘Category’] == ‘Electronics’]Right here, I simply wrapped the situation within the DataFrame. And with that, we get this output

Significantly better, proper? Let’s transfer on
Filter rows by numeric situation
Let’s attempt to retrieve data the place the order amount is bigger than 2. It’s fairly simple.
# Filter rows by numeric situation
# Instance: Orders the place Amount > 2
df_sales[‘Quantity’] > 2Right here, I’m utilizing the better than > operator. Just like our output above, we’re gonna get a Boolean consequence with True and False values. Let’s repair it up actual fast.

And there we go!
Filter by date situation
Filtering by date is simple. As an example.
# Filter by date situation
# Instance: Orders positioned after “2023–01–08”
df_sales[df_sales[“OrderDate”] > “2023–01–08”]This checks for orders positioned after January 8, 2023. And right here’s the output.

The cool factor about Pandas is that it converts string knowledge varieties to dates routinely. In circumstances the place you encounter an error. You may need to convert to a date earlier than filtering utilizing the to_datetime() operate. Right here’s an instance
df[“OrderDate”] = pd.to_datetime(df[“OrderDate”])This converts our OrderDate column to a date knowledge sort. Let’s kick issues up a notch.
Filtering by A number of Situations (AND, OR, NOT)
Pandas permits us to filter on a number of circumstances utilizing logical operators. Nevertheless, these operators are totally different from Python’s built-in operators like (and, or, not). Listed below are the logical operators you’ll be working with probably the most
& (Logical AND)
The ampersand (&) image represents AND in pandas. We use this once we’re attempting to fulfil two circumstances. On this case, each circumstances should be true. As an example, let’s retrieve orders from the “Furnishings” class the place Worth > 500.
# A number of circumstances (AND)
# Instance: Orders from “Furnishings” the place Worth > 500
df_sales[(df_sales[“Category”] == “Furnishings”) & (df_sales[“Price”] > 500)]Let’s break this down. Right here, we have now two circumstances. One which retrieves orders within the Furnishings class and one other that filters for costs > 500. Utilizing the &, we’re capable of mix each circumstances.
Right here’s the consequence.

One file was managed to be retrieved. it, it meets our situation. Let’s do the identical for OR
| (Logical OR)
The |,vertical bar image is used to characterize OR in pandas. On this case, at the least one of many corresponding parts ought to be True. As an example, let’s retrieve data with orders from the “North” area OR “East” area.
# A number of circumstances (OR)
# Instance: Orders from “North” area OR “East” area.
df_sales[(df_sales[“Region”] == “North”) | (df_sales[“Region”] == “East”)]Right here’s the output

Filter with isin()
Let’s say I need to retrieve orders from a number of prospects. I may all the time use the & operator. As an example
df_sales[(df_sales[‘Customer’] == ‘Alice’) | (df_sales[‘Customer’] == ‘Charlie’)]Output:

Nothing improper with that. However there’s a greater and simpler manner to do that. That’s through the use of the isin() operate. Right here’s the way it works
# Orders from prospects ["Alice", "Diana", "James"].
df_sales[df_sales[“Customer”].isin([“Alice”, “Diana”, “James”])]Output:

The code is far simpler and cleaner. Utilizing the isin() operate, I can add as many parameters as I need. Let’s transfer on to some extra superior filtering.
Filter utilizing string matching
One in every of Pandas’ highly effective however underused features is string matching. It helps a ton in knowledge cleansing duties while you’re attempting to go looking by patterns within the data in your DataFrame. Just like the LIKE operator in SQL. As an example, let’s retrieve prospects whose identify begins with “A”.
# Prospects whose identify begins with "A".
df_sales[df_sales[“Customer”].str.startswith(“A”)]Output:

Pandas provides you the .str accessor to make use of string features. Right here’s one other instance
# Merchandise ending with “high” (e.g., Laptop computer).
df_sales[df_sales[“Product”].str.endswith(“high”)]Output:

Filter utilizing question() methodology
If you happen to’re coming from a SQL background, this methodology could be so useful for you. Let’s attempt to retrieve orders from the electronics class the place the amount > 2. It might all the time go like this.
df_sales[(df_sales[“Category”] == “Electronics”) & (df_sales[“Quantity”] >= 2)]Output:
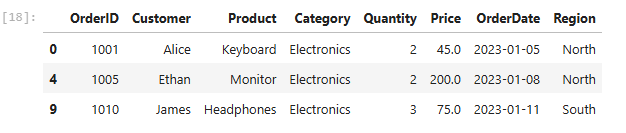
However if you happen to’re somebody attempting to usher in your SQL sauce. This may be just right for you as an alternative
df.question(“Class == ‘Electronics’ and Amount >= 2”)You’ll get the identical output above. Fairly much like SQL if you happen to ask me, and also you’ll be capable of ditch the & image. I’m gonna be utilizing this methodology very often.
Filter by column values in a spread
Pandas means that you can retrieve a spread of values. As an example, Orders the place the Worth is between 50 and 500 would go like this
# Orders the place the Worth is between 50 and 500
df_sales[df_sales[“Price”].between(50, 500)]Output:

Fairly simple.
Filter lacking values (NaN)
That is in all probability probably the most useful operate as a result of, as a knowledge analyst, one of many knowledge cleansing duties you’ll be engaged on probably the most is filtering out lacking values. To do that in Pandas is simple. That’s through the use of the notna() operate. Let’s filter rows the place Worth just isn’t null.
# filter rows the place Worth just isn't null.
df_sales[df_sales[“Price”].notna()]Output:

And there you go. I don’t actually discover the distinction, although, however I’m gonna belief it’s carried out.
Conclusion
The subsequent time you open a messy CSV and surprise “The place do I even begin?”, strive filtering first. It’s the quickest solution to lower by the noise and discover the story hidden in your knowledge.
The transition to Python for knowledge evaluation used to really feel like an enormous step, coming from a SQL background. However for some motive, Pandas appears manner simpler and fewer time-consuming for me for filtering knowledge
The cool half about that is that these similar methods work regardless of the dataset — gross sales numbers, survey responses, internet analytics, you identify it.
I hope you discovered this text useful.
I write these articles as a solution to take a look at and strengthen my very own understanding of technical ideas — and to share what I’m studying with others who could be on the identical path. Be happy to share with others. Let’s study and develop collectively. Cheers!
Be happy to say hello on any of those platforms