
When you solely take a look at automated scores, most LLMs appear nice—till they write one thing subtly mistaken, dangerous, or off-tone. That’s the hole between what static benchmarks measure and what your customers really need. On this information, we present mix human judgment (HITL) with automation so your LLM benchmarking displays truthfulness, security, and area match—not simply token-level accuracy.
What LLM Benchmarking Actually Measures
Automated metrics and leaderboards are quick and repeatable. Accuracy on multiple-choice duties, BLEU/ROUGE for textual content similarity, and perplexity for language modeling give directional indicators. However they usually miss reasoning chains, factual grounding, and coverage compliance—particularly in high-stakes contexts. That’s why fashionable applications emphasize multi-metric, clear reporting and state of affairs realism.
Automated metrics & static take a look at units
Consider traditional metrics as a speedometer—nice for telling you how briskly you’re occurring a clean freeway. However they don’t inform you if the brakes work within the rain. BLEU/ROUGE/perplexity assist with comparability, however they are often gamed by memorization or surface-level match.
The place they fall brief
Actual customers carry ambiguity, area jargon, conflicting objectives, and altering rules. Static take a look at units hardly ever seize that. In consequence, purely automated benchmarks overestimate mannequin readiness for complicated enterprise duties. Group efforts like HELM/AIR-Bench handle this by masking extra dimensions (robustness, security, disclosure) and publishing clear, evolving suites.
The Case for Human Analysis in LLM Benchmarks
Some qualities stay stubbornly human: tone, helpfulness, delicate correctness, cultural appropriateness, and danger. Human raters—correctly educated and calibrated—are the very best devices we have now for these. The trick is utilizing them selectively and systematically, so prices keep manageable whereas high quality stays excessive.
When to contain people

- Ambiguity: directions admit a number of believable solutions.
- Excessive-risk: healthcare, finance, authorized, safety-critical help.
- Area nuance: business jargon, specialised reasoning.
- Disagreement indicators: automated scores battle or range broadly.
Designing rubrics & calibration (easy instance)
Begin with a 1–5 scale for correctness, groundedness, and coverage alignment. Present 2–3 annotated examples per rating. Run brief calibration rounds: raters rating a shared batch, then evaluate rationales to tighten consistency. Observe inter-rater settlement and require adjudication for borderline circumstances.
Strategies: From LLM-as-a-Decide to True HITL
LLM-as-a-Decide (utilizing a mannequin to grade one other mannequin) is helpful for triage: it’s fast, low cost, and works effectively for simple checks. However it may share the identical blind spots—hallucinations, spurious correlations, or “grade inflation.” Use it to prioritize circumstances for human assessment, to not exchange it.
A sensible hybrid pipeline
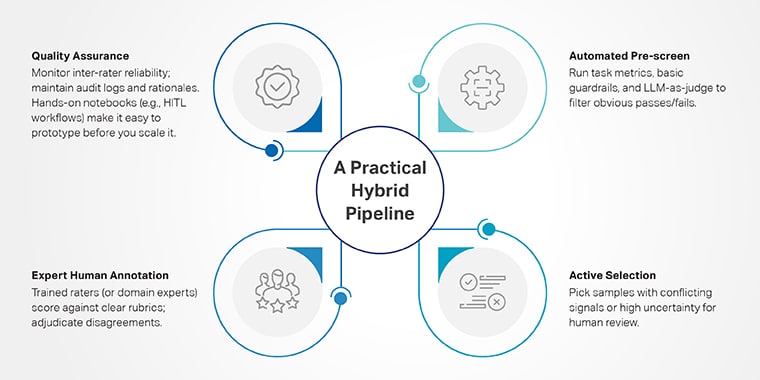
- Automated pre-screen: run process metrics, fundamental guardrails, and LLM-as-judge to filter apparent passes/fails.
- Lively choice: decide samples with conflicting indicators or excessive uncertainty for human assessment.
- Professional human annotation: educated raters (or area consultants) rating towards clear rubrics; adjudicate disagreements.
- High quality assurance: monitor inter-rater reliability; preserve audit logs and rationales. Fingers-on notebooks (e.g., HITL workflows) make it straightforward to prototype this loop earlier than you scale it.
Comparability Desk: Automated vs LLM-as-Decide vs HITL
Security & Threat Benchmarks Are Totally different
Regulators and requirements our bodies anticipate evaluations that doc dangers, take a look at lifelike eventualities, and exhibit oversight. The NIST AI RMF (2024 GenAI Profile) gives a shared vocabulary and practices; the NIST GenAI Analysis program is standing up domain-specific checks; and HELM/AIR-Bench spotlights multi-metric, clear outcomes. Use these to anchor your governance narrative.
What to gather for security audits
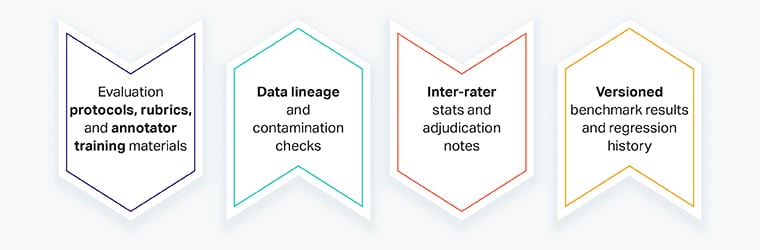
- Analysis protocols, rubrics, and annotator coaching supplies
- Knowledge lineage and contamination checks
- Inter-rater stats and adjudication notes
- Versioned benchmark outcomes and regression historical past
Mini-Story: Chopping False Positives in Banking KYC
A financial institution’s KYC analyst group examined two fashions for summarizing compliance alerts. Automated scores have been similar. Throughout a HITL move, raters flagged that Mannequin A steadily dropped detrimental qualifiers (“no prior sanctions”), flipping meanings. After adjudication, the financial institution selected Mannequin B and up to date prompts. False positives dropped 18% in every week, releasing analysts for actual investigations. (The lesson: automated scores missed a delicate, high-impact error; HITL caught it.)