
distributions are probably the most generally used, a whole lot of real-world knowledge sadly isn’t regular. When confronted with extraordinarily skewed knowledge, it’s tempting for us to make the most of log transformations to normalize the distribution and stabilize the variance. I lately labored on a venture analyzing the power consumption of coaching AI fashions, utilizing knowledge from Epoch AI [1]. There is no such thing as a official knowledge on power utilization of every mannequin, so I calculated it by multiplying every mannequin’s energy draw with its coaching time. The brand new variable, Power (in kWh), was extremely right-skewed, together with some excessive and overdispersed outliers (Fig. 1).
To handle this skewness and heteroskedasticity, my first intuition was to use a log transformation to the Power variable. The distribution of log(Power) regarded rather more regular (Fig. 2), and a Shapiro-Wilk take a look at confirmed the borderline normality (p ≈ 0.5).

Modeling Dilemma: Log Transformation vs Log Hyperlink
The visualization regarded good, however once I moved on to modeling, I confronted a dilemma: Ought to I mannequin the log-transformed response variable (log(Y) ~ X), or ought to I mannequin the authentic response variable utilizing a log hyperlink operate (Y ~ X, hyperlink = “log")? I additionally thought of two distributions — Gaussian (regular) and Gamma distributions — and mixed every distribution with each log approaches. This gave me 4 totally different fashions as beneath, all fitted utilizing R’s Generalized Linear Fashions (GLM):
all_gaussian_log_link <- glm(Energy_kWh ~ Parameters +
Training_compute_FLOP +
Training_dataset_size +
Training_time_hour +
Hardware_quantity +
Training_hardware,
household = gaussian(hyperlink = "log"), knowledge = df)
all_gaussian_log_transform <- glm(log(Energy_kWh) ~ Parameters +
Training_compute_FLOP +
Training_dataset_size +
Training_time_hour +
Hardware_quantity +
Training_hardware,
knowledge = df)
all_gamma_log_link <- glm(Energy_kWh ~ Parameters +
Training_compute_FLOP +
Training_dataset_size +
Training_time_hour +
Hardware_quantity +
Training_hardware + 0,
household = Gamma(hyperlink = "log"), knowledge = df)
all_gamma_log_transform <- glm(log(Energy_kWh) ~ Parameters +
Training_compute_FLOP +
Training_dataset_size +
Training_time_hour +
Hardware_quantity +
Training_hardware + 0,
household = Gamma(), knowledge = df)Mannequin Comparability: AIC and Diagnostic Plots
I in contrast the 4 fashions utilizing Akaike Info Criterion (AIC), which is an estimator of prediction error. Usually, the decrease the AIC, the higher the mannequin suits.
AIC(all_gaussian_log_link, all_gaussian_log_transform, all_gamma_log_link, all_gamma_log_transform)
df AIC
all_gaussian_log_link 25 2005.8263
all_gaussian_log_transform 25 311.5963
all_gamma_log_link 25 1780.8524
all_gamma_log_transform 25 352.5450Among the many 4 fashions, fashions utilizing log-transformed outcomes have a lot decrease AIC values than those utilizing log hyperlinks. Because the distinction in AIC between log-transformed and log-link fashions was substantial (311 and 352 vs 1780 and 2005), I additionally examined the diagnostics plots to additional validate that log-transformed fashions match higher:




Based mostly on the AIC values and diagnostic plots, I made a decision to maneuver ahead with the log-transformed Gamma mannequin, because it had the second-lowest AIC worth and its Residuals vs Fitted plot appears to be like higher than that of the log-transformed Gaussian mannequin.
I proceeded to discover which explanatory variables had been helpful and which interactions could have been vital. The ultimate mannequin I chosen was:
glm(method = log(Energy_kWh) ~ Training_time_hour * Hardware_quantity +
Training_hardware + 0, household = Gamma(), knowledge = df)Deciphering Coefficients
Nevertheless, once I began decoding the mannequin’s coefficients, one thing felt off. Since solely the response variable was log-transformed, the consequences of the predictors are multiplicative, and we have to exponentiate the coefficients to transform them again to the unique scale. A one-unit enhance in 𝓍 multiplies the end result 𝓎 by exp(β), or every further unit in 𝓍 results in a (exp(β) — 1) × 100 % change in 𝓎 [2].
Trying on the outcomes desk of the mannequin beneath, now we have Training_time_hour, Hardware_quantity, and their interplay time period Training_time_hour:Hardware_quantity are steady variables, so their coefficients signify slopes. In the meantime, since I specified +0 within the mannequin method, all ranges of the explicit Training_hardware act as intercepts, which means that every {hardware} kind acted because the intercept β₀ when its corresponding dummy variable was lively.
> glm(method = log(Energy_kWh) ~ Training_time_hour * Hardware_quantity +
Training_hardware + 0, household = Gamma(), knowledge = df)
Coefficients:
Estimate Std. Error t worth Pr(>|t|)
Training_time_hour -1.587e-05 3.112e-06 -5.098 5.76e-06 ***
Hardware_quantity -5.121e-06 1.564e-06 -3.275 0.00196 **
Training_hardwareGoogle TPU v2 1.396e-01 2.297e-02 6.079 1.90e-07 ***
Training_hardwareGoogle TPU v3 1.106e-01 7.048e-03 15.696 < 2e-16 ***
Training_hardwareGoogle TPU v4 9.957e-02 7.939e-03 12.542 < 2e-16 ***
Training_hardwareHuawei Ascend 910 1.112e-01 1.862e-02 5.969 2.79e-07 ***
Training_hardwareNVIDIA A100 1.077e-01 6.993e-03 15.409 < 2e-16 ***
Training_hardwareNVIDIA A100 SXM4 40 GB 1.020e-01 1.072e-02 9.515 1.26e-12 ***
Training_hardwareNVIDIA A100 SXM4 80 GB 1.014e-01 1.018e-02 9.958 2.90e-13 ***
Training_hardwareNVIDIA GeForce GTX 285 3.202e-01 7.491e-02 4.275 9.03e-05 ***
Training_hardwareNVIDIA GeForce GTX TITAN X 1.601e-01 2.630e-02 6.088 1.84e-07 ***
Training_hardwareNVIDIA GTX Titan Black 1.498e-01 3.328e-02 4.501 4.31e-05 ***
Training_hardwareNVIDIA H100 SXM5 80GB 9.736e-02 9.840e-03 9.894 3.59e-13 ***
Training_hardwareNVIDIA P100 1.604e-01 1.922e-02 8.342 6.73e-11 ***
Training_hardwareNVIDIA Quadro P600 1.714e-01 3.756e-02 4.562 3.52e-05 ***
Training_hardwareNVIDIA Quadro RTX 4000 1.538e-01 3.263e-02 4.714 2.12e-05 ***
Training_hardwareNVIDIA Quadro RTX 5000 1.819e-01 4.021e-02 4.524 3.99e-05 ***
Training_hardwareNVIDIA Tesla K80 1.125e-01 1.608e-02 6.993 7.54e-09 ***
Training_hardwareNVIDIA Tesla V100 DGXS 32 GB 1.072e-01 1.353e-02 7.922 2.89e-10 ***
Training_hardwareNVIDIA Tesla V100S PCIe 32 GB 9.444e-02 2.030e-02 4.653 2.60e-05 ***
Training_hardwareNVIDIA V100 1.420e-01 1.201e-02 11.822 8.01e-16 ***
Training_time_hour:Hardware_quantity 2.296e-09 9.372e-10 2.450 0.01799 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for Gamma household taken to be 0.05497984)
Null deviance: NaN on 70 levels of freedom
Residual deviance: 3.0043 on 48 levels of freedom
AIC: 345.39When changing the slopes to % change in response variable, the impact of every steady variable was nearly zero, even barely detrimental: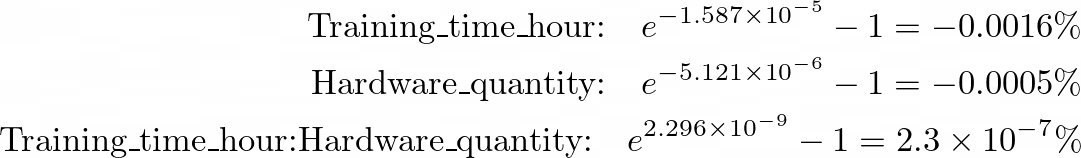
All of the intercepts had been additionally transformed again to simply round 1 kWh on the unique scale. The outcomes didn’t make any sense as a minimum of one of many slopes ought to develop together with the big power consumption. I puzzled if utilizing the log-linked mannequin with the identical predictors could yield totally different outcomes, so I match the mannequin once more:
glm(method = Energy_kWh ~ Training_time_hour * Hardware_quantity +
Training_hardware + 0, household = Gamma(hyperlink = "log"), knowledge = df)
Coefficients:
Estimate Std. Error t worth Pr(>|t|)
Training_time_hour 1.818e-03 1.640e-04 11.088 7.74e-15 ***
Hardware_quantity 7.373e-04 1.008e-04 7.315 2.42e-09 ***
Training_hardwareGoogle TPU v2 7.136e+00 7.379e-01 9.670 7.51e-13 ***
Training_hardwareGoogle TPU v3 1.004e+01 3.156e-01 31.808 < 2e-16 ***
Training_hardwareGoogle TPU v4 1.014e+01 4.220e-01 24.035 < 2e-16 ***
Training_hardwareHuawei Ascend 910 9.231e+00 1.108e+00 8.331 6.98e-11 ***
Training_hardwareNVIDIA A100 1.028e+01 3.301e-01 31.144 < 2e-16 ***
Training_hardwareNVIDIA A100 SXM4 40 GB 1.057e+01 5.635e-01 18.761 < 2e-16 ***
Training_hardwareNVIDIA A100 SXM4 80 GB 1.093e+01 5.751e-01 19.005 < 2e-16 ***
Training_hardwareNVIDIA GeForce GTX 285 3.042e+00 1.043e+00 2.916 0.00538 **
Training_hardwareNVIDIA GeForce GTX TITAN X 6.322e+00 7.379e-01 8.568 3.09e-11 ***
Training_hardwareNVIDIA GTX Titan Black 6.135e+00 1.047e+00 5.862 4.07e-07 ***
Training_hardwareNVIDIA H100 SXM5 80GB 1.115e+01 6.614e-01 16.865 < 2e-16 ***
Training_hardwareNVIDIA P100 5.715e+00 6.864e-01 8.326 7.12e-11 ***
Training_hardwareNVIDIA Quadro P600 4.940e+00 1.050e+00 4.705 2.18e-05 ***
Training_hardwareNVIDIA Quadro RTX 4000 5.469e+00 1.055e+00 5.184 4.30e-06 ***
Training_hardwareNVIDIA Quadro RTX 5000 4.617e+00 1.049e+00 4.401 5.98e-05 ***
Training_hardwareNVIDIA Tesla K80 8.631e+00 7.587e-01 11.376 3.16e-15 ***
Training_hardwareNVIDIA Tesla V100 DGXS 32 GB 9.994e+00 6.920e-01 14.443 < 2e-16 ***
Training_hardwareNVIDIA Tesla V100S PCIe 32 GB 1.058e+01 1.047e+00 10.105 1.80e-13 ***
Training_hardwareNVIDIA V100 9.208e+00 3.998e-01 23.030 < 2e-16 ***
Training_time_hour:Hardware_quantity -2.651e-07 6.130e-08 -4.324 7.70e-05 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for Gamma household taken to be 1.088522)
Null deviance: 2.7045e+08 on 70 levels of freedom
Residual deviance: 1.0593e+02 on 48 levels of freedom
AIC: 1775This time, Training_time and Hardware_quantity would enhance the full power consumption by 0.18% per further hour and 0.07% per further chip, respectively. In the meantime, their interplay would lower the power use by 2 × 10⁵%. These outcomes made extra sense as Training_time can attain as much as 7000 hours and Hardware_quantity as much as 16000 models.

To visualise the variations higher, I created two plots evaluating the predictions (proven as dashed traces) from each fashions. The left panel used the log-transformed Gamma GLM mannequin, the place the dashed traces had been practically flat and near zero, nowhere close to the fitted stable traces of uncooked knowledge. Then again, the proper panel used log-linked Gamma GLM mannequin, the place the dashed traces aligned rather more carefully with the precise fitted traces.
test_data <- df[, c("Training_time_hour", "Hardware_quantity", "Training_hardware")]
prediction_data <- df %>%
mutate(
pred_energy1 = exp(predict(glm3, newdata = test_data)),
pred_energy2 = predict(glm3_alt, newdata = test_data, kind = "response"),
)
y_limits <- c(min(df$Energy_KWh, prediction_data$pred_energy1, prediction_data$pred_energy2),
max(df$Energy_KWh, prediction_data$pred_energy1, prediction_data$pred_energy2))
p1 <- ggplot(df, aes(x = Hardware_quantity, y = Energy_kWh, coloration = Training_time_group)) +
geom_point(alpha = 0.6) +
geom_smooth(methodology = "lm", se = FALSE) +
geom_smooth(knowledge = prediction_data, aes(y = pred_energy1), methodology = "lm", se = FALSE,
linetype = "dashed", measurement = 1) +
scale_y_log10(limits = y_limits) +
labs(x="{Hardware} Amount", y = "log of Power (kWh)") +
theme_minimal() +
theme(legend.place = "none")
p2 <- ggplot(df, aes(x = Hardware_quantity, y = Energy_kWh, coloration = Training_time_group)) +
geom_point(alpha = 0.6) +
geom_smooth(methodology = "lm", se = FALSE) +
geom_smooth(knowledge = prediction_data, aes(y = pred_energy2), methodology = "lm", se = FALSE,
linetype = "dashed", measurement = 1) +
scale_y_log10(limits = y_limits) +
labs(x="{Hardware} Amount", coloration = "Coaching Time Degree") +
theme_minimal() +
theme(axis.title.y = element_blank())
p1 + p2
Why Log Transformation Fails
To grasp the rationale why the log-transformed mannequin can’t seize the underlying results because the log-linked one, let’s stroll by means of what occurs once we apply a log transformation to the response variable:
Let’s say Y is the same as some operate of X plus the error time period:

Once we apply a log remodeling to Y, we are literally compressing each f(X) and the error:

Which means we’re modeling an entire new response variable, log(Y). Once we plug in our personal operate g(X)— in my case g(X) = Training_time_hour*Hardware_quantity + Training_hardware — it’s making an attempt to seize the mixed results of each the “shrunk” f(X) and error time period.
In distinction, once we use a log hyperlink, we’re nonetheless modeling the unique Y, not the reworked model. As an alternative, the mannequin exponentiates our personal operate g(X) to foretell Y.

The mannequin then minimizes the distinction between the precise Y and the anticipated Y. That means, the error phrases stays intact on the unique scale:

Conclusion
Log-transforming a variable isn’t the identical as utilizing a log hyperlink, and it might not at all times yield dependable outcomes. Below the hood, a log transformation alters the variable itself and distorts each the variation and noise. Understanding this refined mathematical distinction behind your fashions is simply as essential as looking for the best-fitting mannequin.
[1] Epoch AI. Information on Notable AI Fashions. Retrieved from https://epoch.ai/data/notable-ai-models
[2] College of Virginia Library. Deciphering Log Transformations in a Linear Mannequin. Retrieved from https://library.virginia.edu/data/articles/interpreting-log-transformations-in-a-linear-model